As a teenager, I began to suffer with chronic and ongoing insomnia that has stayed with me for all of my adult life with very few periods of real respite. However, rather than turn this into a sob story, I’ve managed to come up with a really interesting data story!
In the search for triggers and patterns, I decided to buy a wearable fitness tracker and keep a tally of my nightly quality sleep hours. Around the same time, I finally had the self-awareness to realise that a lot of my worst nights seemed to be accompanied by digestive disturbances, even so to hypothesise that certain food groups may be acting as triggers or exacerbating the problem. I decided to keep a food diary alongside the sleep data. I might also add that I’m proud of myself for not skipping a day during the collection period.
This post will detail some of the most interesting findings after one year of this fascinating self-study. I want to demonstrate a case for using survival analysis for this dataset, because I’m analysing a time to event (waking up), which is made possible by using the wearable device that tracks quality sleep hours and is agnostic of what time I go to bed or if I wake up in the middle of the night.
As usual with these posts, I don’t print the code inline so we can see the analysis step-by-step, which is more interesting for most people. All the code is then echoed in the appendix.
The raw dataset consists of five variables and 365 observations. The observations are ordered (but not labelled) by date, ranging from 2022-01-01 to 2022-12-31. The second is the dependent variable: time_sleeping, which for simplicity is measured in hrs (float), rather than calculating out minutes and seconds. The remaining four are boolean flags for whether a food group was present or absent in that evening’s meal. The food groups were based on suggestions by my GP and personal observation. Namely, cheese, brassica, (red) meat, and spice (including chili, curry, onions and garlic).
1
2
## vars n mean sd median trimmed mad min max range skew kurtosis se## X1 1 365 5.97 1.61 5.84 5.96 1.63 1.62 10.72 9.1 0.09 -0.24 0.08
The null hypothesis that I can test with these data is that none of these food groups have any effect on my sleep. The alternative is that at least one has an effect. And that’s exactly what I want to know if I am to improve my sleep by changing my eating habits. Hopefully, this knowledge will allow me to continue eating most of the things I enjoy.
A multi-variate linear model would normally be a starting point but there are several potential confounders:
Some evenings, dinner can contain one, two or even three of these food groups. The effects may be hard to isolate.
There is likely to be some auto-regressive influence, for example, two or three nights of poor sleep are sometimes followed by a catch-up night where the mind and body are just exhausted and sleep for longer.
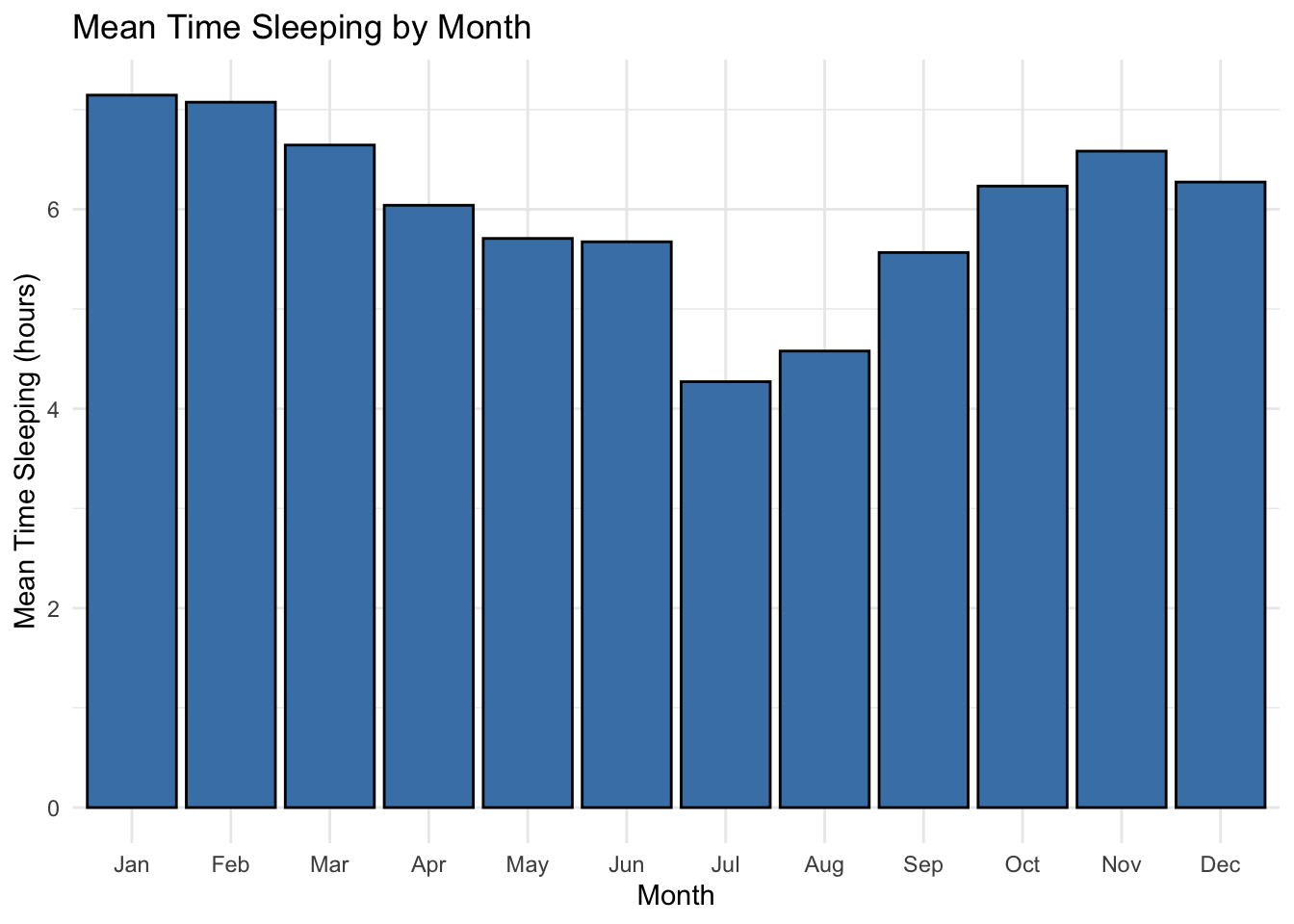
Sleep is highly seasonal, being definitely shorter in summer as the hours of darkness are shorter in Germany, where I live.
Time sleeping is the total time that the fitness tracker detected quality sleep. However, this is a somewhat simplified view because my sleep patterns tend to be broken and interrupted. I go to bed and get up and approximately the same time most days but some nights I have to deal with two to three hours of wakeful restlessness. For simplicity, I’m counting this all as one sleep event of a certain length of time. It was too much trouble to count or measure the sleep interruptions. The resulting data are always a positive real number. That is, there are no nights of negative sleep and any model should reflect this. A linear model, in theory, could return a negative value, so it is necessary to consider some alternatives.
Time-to-event is often modeled using Gamma or Weibull distributions, and well understood within Survival Analytics. So, to test this line of thinking, I would like to compare three models: Linear, Generalized Linear with Gamma family, and a parametric survival model with Weibull distribution.
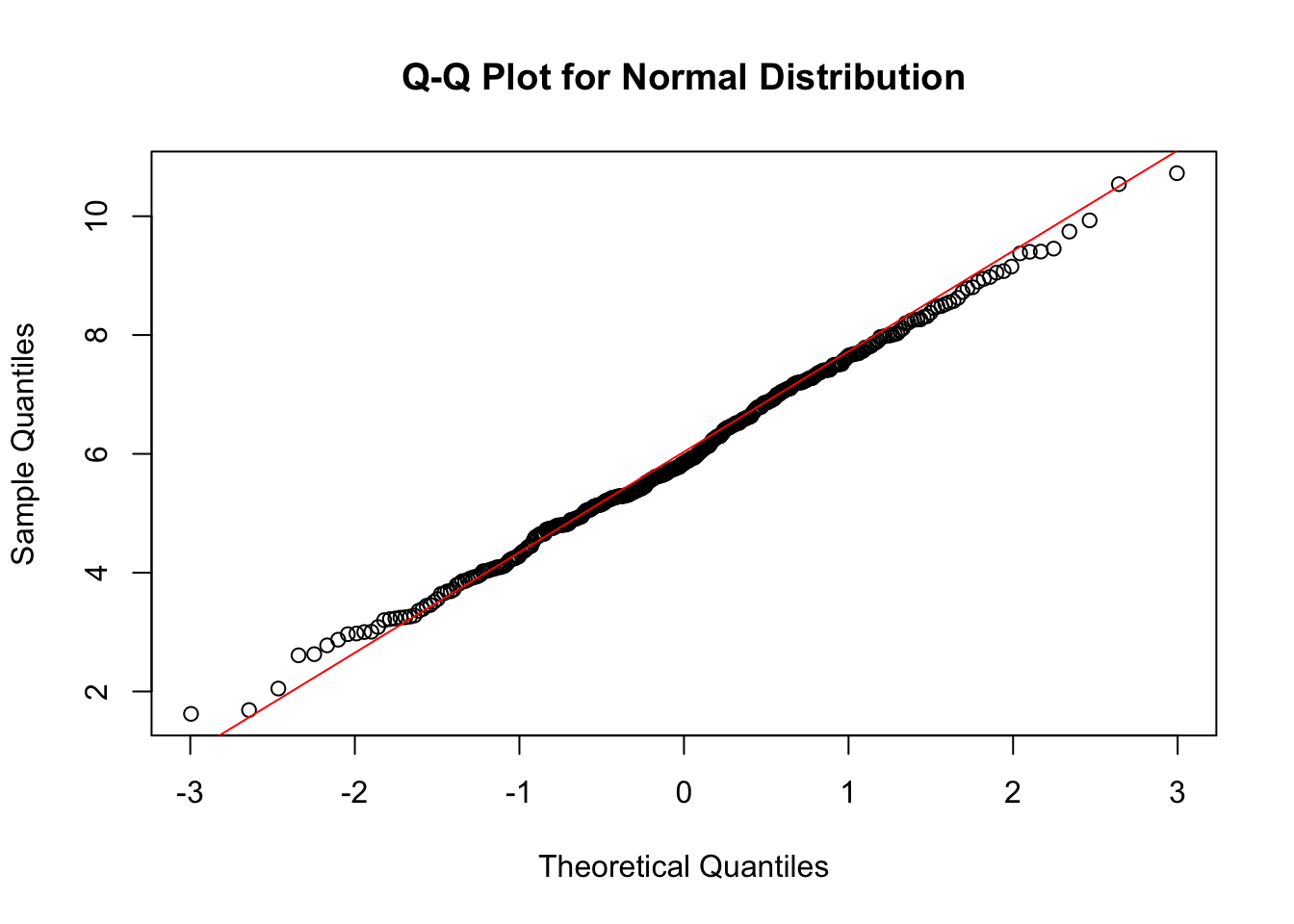
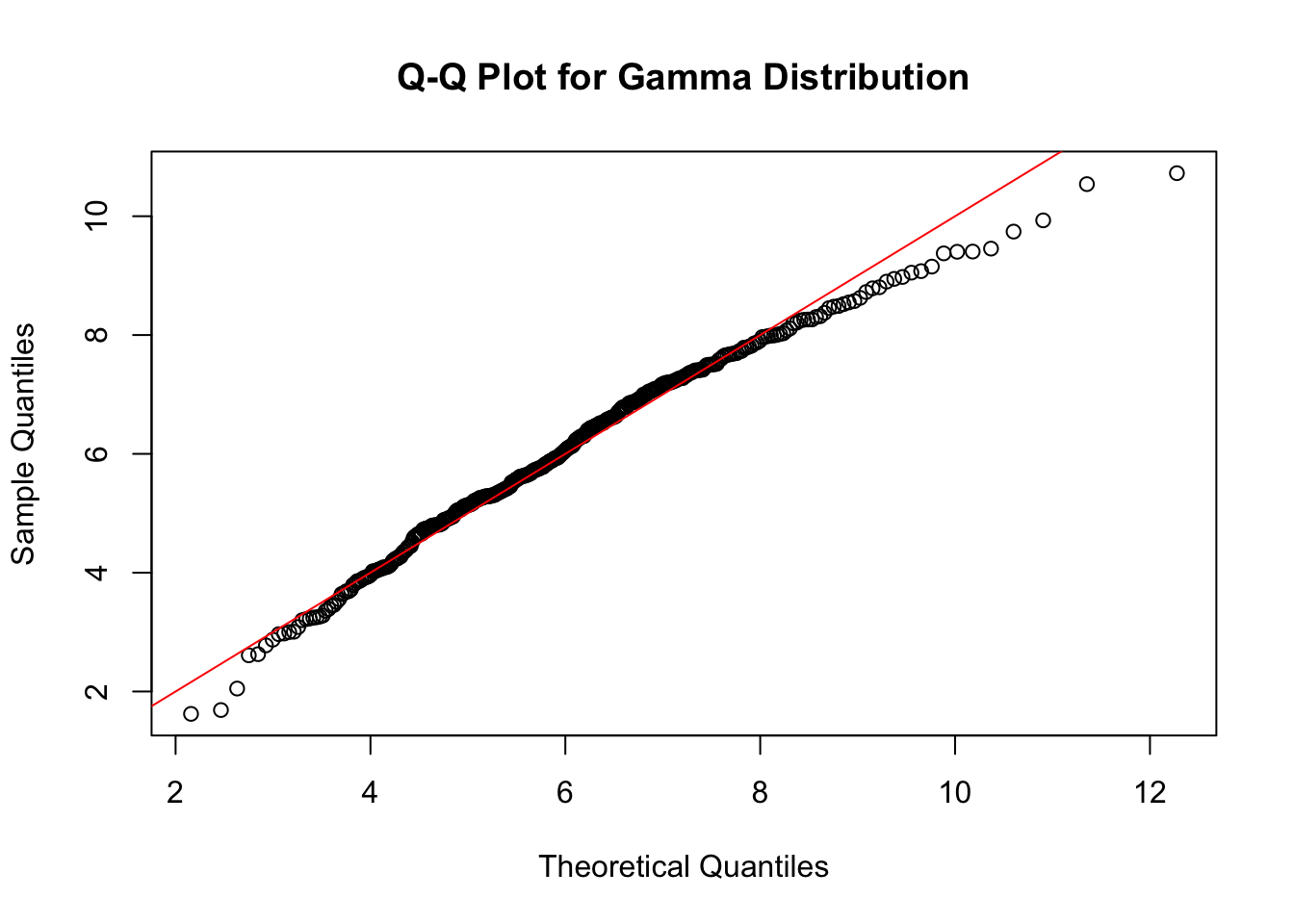
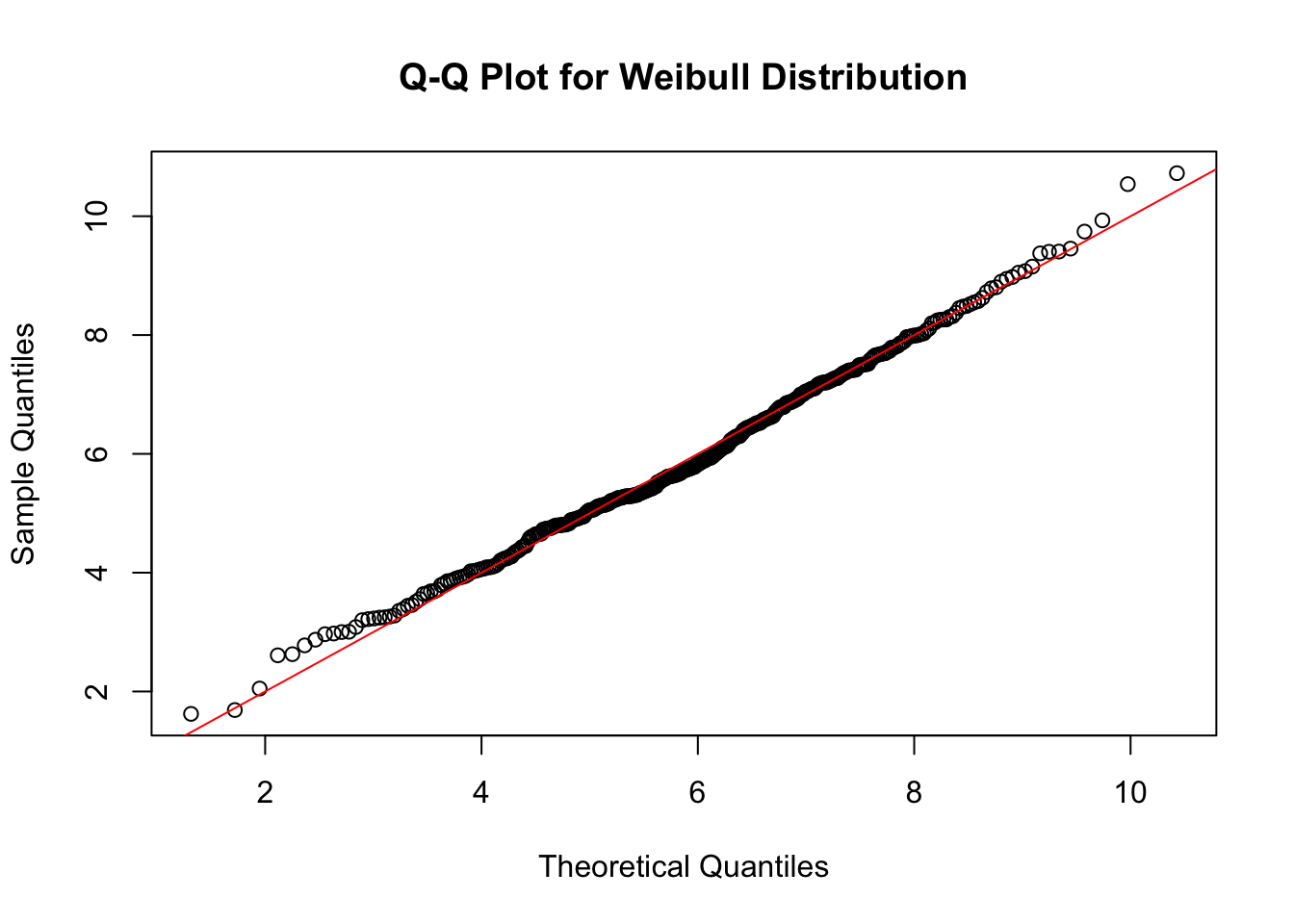
I use the versatile Anderson-Darling test for goodness of fit with the three candidate distributions. Although other tests such as Kolmogorov-Smirnov and Shapiro-Wilks are most common for goodness of fit to the Normal distribution, Anderson-Darling still works well for the Normal, and given the decent sample size and putting aside the likely presence of auto-correlation, it’s very useful to be able to use the same test for all three candidates. Anderson-Darling test is most sensitive to deviations in the tail, and so is an excellent choice for making assessments of fit to both Gamma and Weibull distributions.
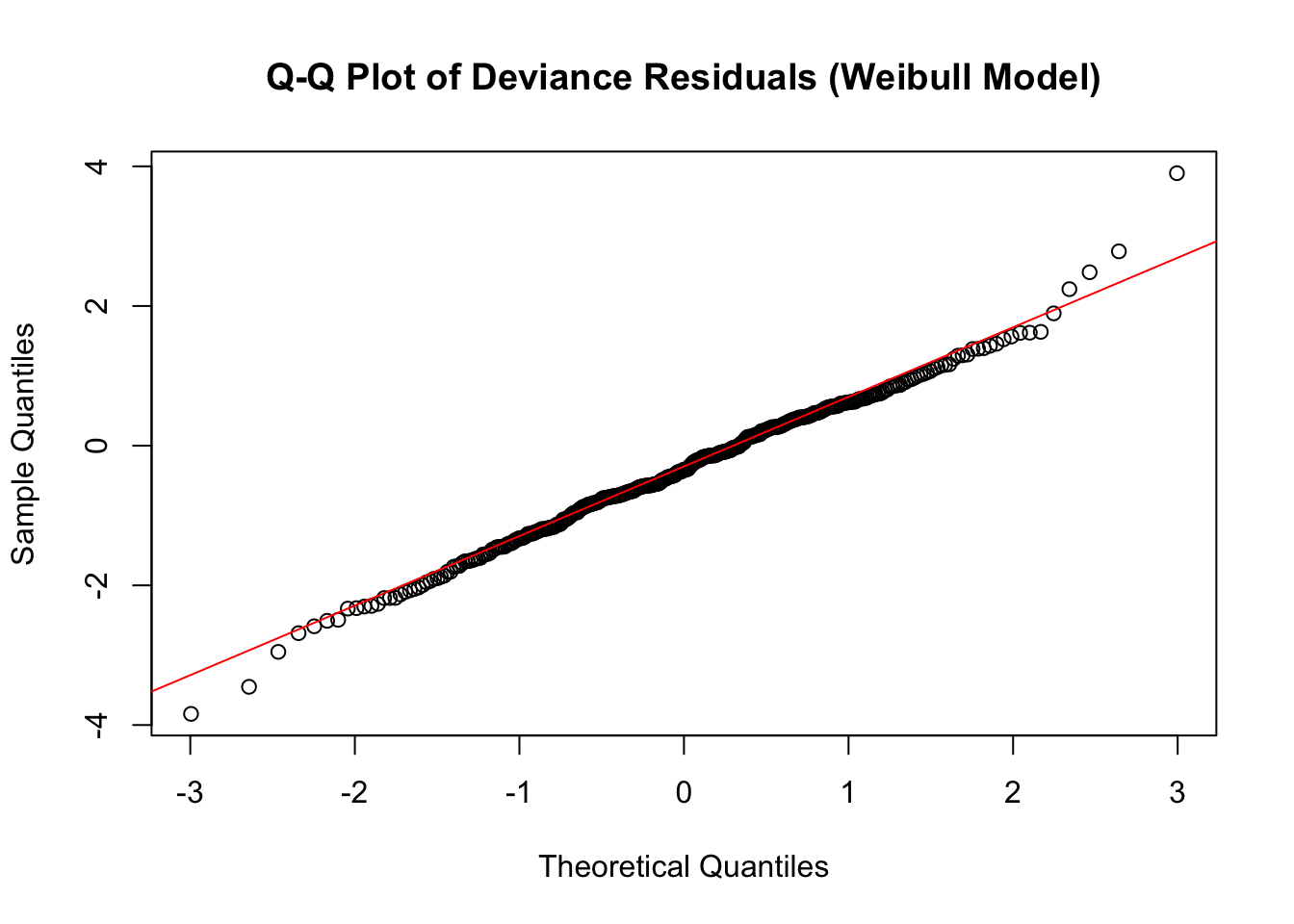
One disadvantage is that the tests assume fixed, known parameters. However, these are unknown and have to be estimated directly from the data to provide to the test routines. This is not recommended practice and can lead to biased results. On this occasion, I will accept the risk because it is outweighed by the convenience of assessing all three fits with the same test. I can apply a further visual check with a Q-Q plot should be enough to confirm or reject the goodness-of-fit test results.
1
2
3
4
5
6
7
8
##
## Anderson-Darling test of goodness-of-fit
## Null hypothesis: Normal distribution
## with parameters mean = 5.97381266124959, sd = 1.61023592966754
## Parameters assumed to be fixed
##
## data: dframe$time_sleeping
## An = 0.41908, p-value = 0.8295
1
2
3
4
5
6
7
8
##
## Anderson-Darling test of goodness-of-fit
## Null hypothesis: Gamma distribution
## with parameters shape = 12.6312583519882, rate = 2.11434807107313
## Parameters assumed to be fixed
##
## data: dframe$time_sleeping
## An = 1.0658, p-value = 0.3245
1
2
3
4
5
6
7
8
##
## Anderson-Darling test of goodness-of-fit
## Null hypothesis: Weibull distribution
## with parameters shape = 4.09387276140609, scale = 6.5788628337449
## Parameters assumed to be fixed
##
## data: dframe$time_sleeping
## An = 0.60368, p-value = 0.6444
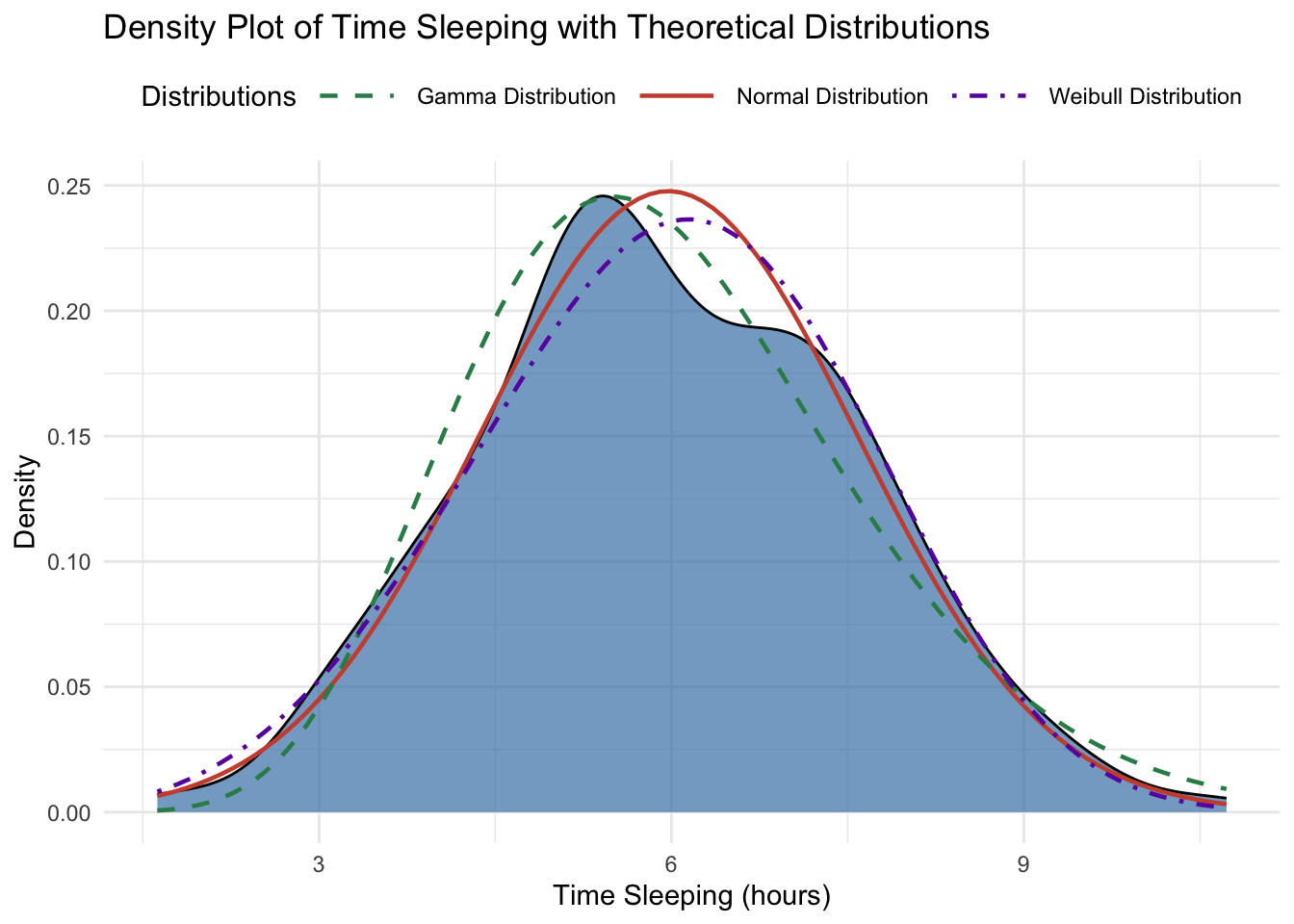
It’s worth comparing these theoretical distributions with the sample to understand why all three tests suggests a goodness of fit. Clearly there are pros and cons to using any of these distributions to model the data. The Gamma density curve is better aligned with the sample peak but the over-estimated skew is evident. It could be biased to under-estimate extreme values. Without calculating the KL-divergence, the Weibull has the visual appearance of balancing out the mass around the peak better than the normal but looks like it will be biased to over-estimating the mean. However, it is guaranteed never to return a negative real value, unlike the Normal. The Normal distribution is still a good fit, and comes with the richest literature and support. I will proceed with the three-way comparison.
To mitigate the possibility of auto-regressive, trend and combined food-trigger confounders, I add the following features:
auto-regressive features (up to four days of lag)
testing with daily index vs. month number vs. calendar quarter for isolating the seasonal trend
combine the four Booleans variables bitwise to create a factor variable with a unique value for each combination of one, two and three food triggers
For each model family, I tested different model formulas, trying either trend (linear unit increase per day), month (number), month (factor), quarter (number), and quarter (factor) for the time based component, with and without quadratic components for numeric time-based components. I tried with the four separate Boolean food triggers, and separately with the unique combination food triggers (factor). When the best performing model was identified in each family, I removed non-significant variables among the four auto-regressive components.
In all three cases, there was complete alignment on the parameter set that yielded the best model. The month (factor) was sufficient to capture differences in sleeping time attributable to changes in daylight hours, while keeping the food triggers as separate Booleans was better for explaining the variance than combining them into a single, multi-level factor. This is likely because the combined factor almost doubles the number of levels.
Finally, it was clear that only the one day lag was needed to account for catchup sleep after a previous bad night.
I’ll skip the model selection and just report the best performing model from each family.
Based on the AIC results, it appears as though the parametric survival model with Weibull distribution is the best of the three models, and the Generalized Linear Model with Gamma distribition and inverse link function is the least well performing. I will conduct a likelihood ratio test to see if the differences between the three models are significant.
1
## [1] WB > LM, Likelihood Ratio Test Statistic: 21.711, p-value: 0.000
1
## [1] WB > GLM, Likelihood Ratio Test Statistic: 46.382, p-value: 0.000
1
## [1] LM > GLM, Likelihood Ratio Test Statistic: 24.671, p-value: 0.000
These results suggest that the parametric survival model with Weibull distribution is the best model over all by a significant margin.
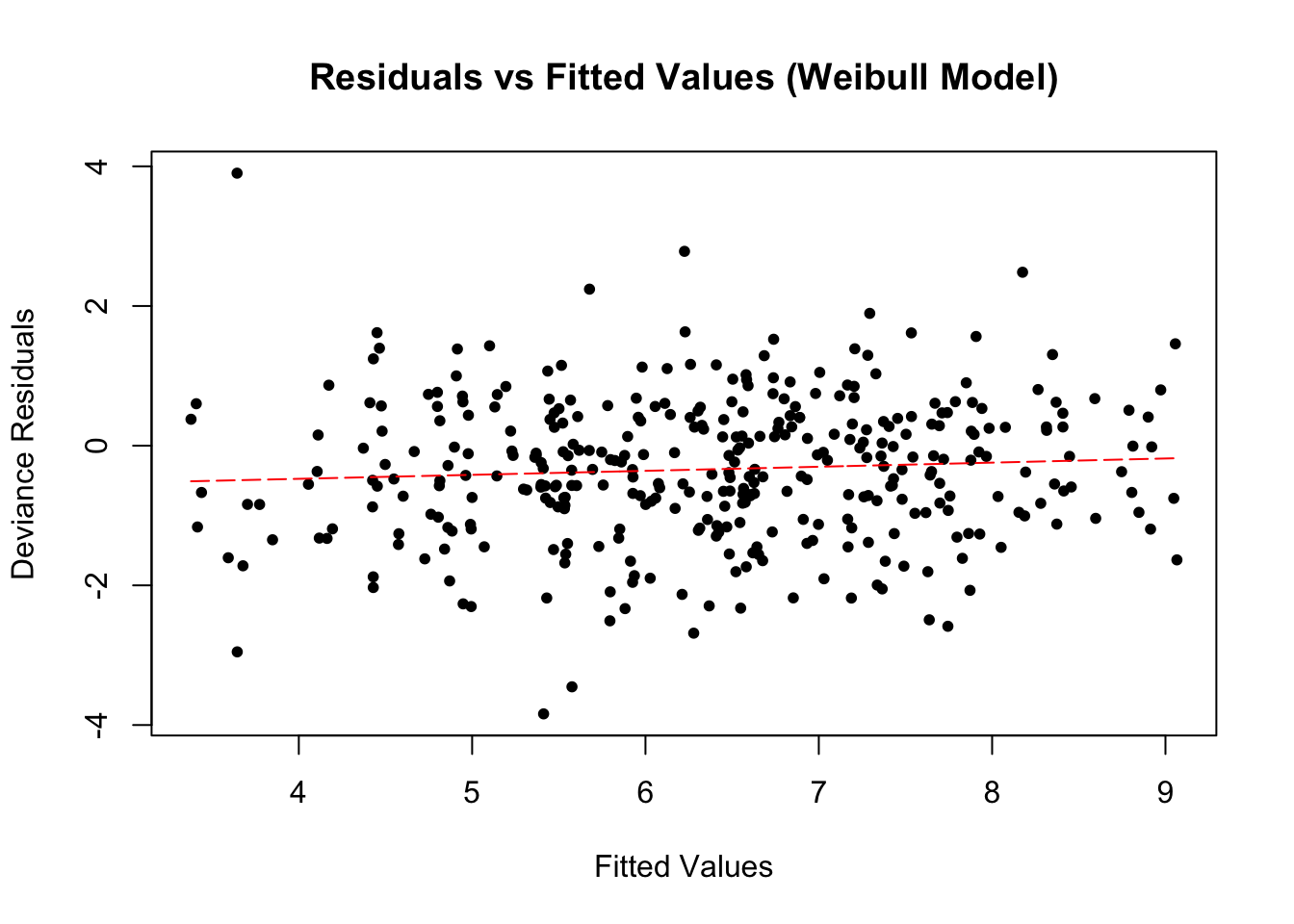
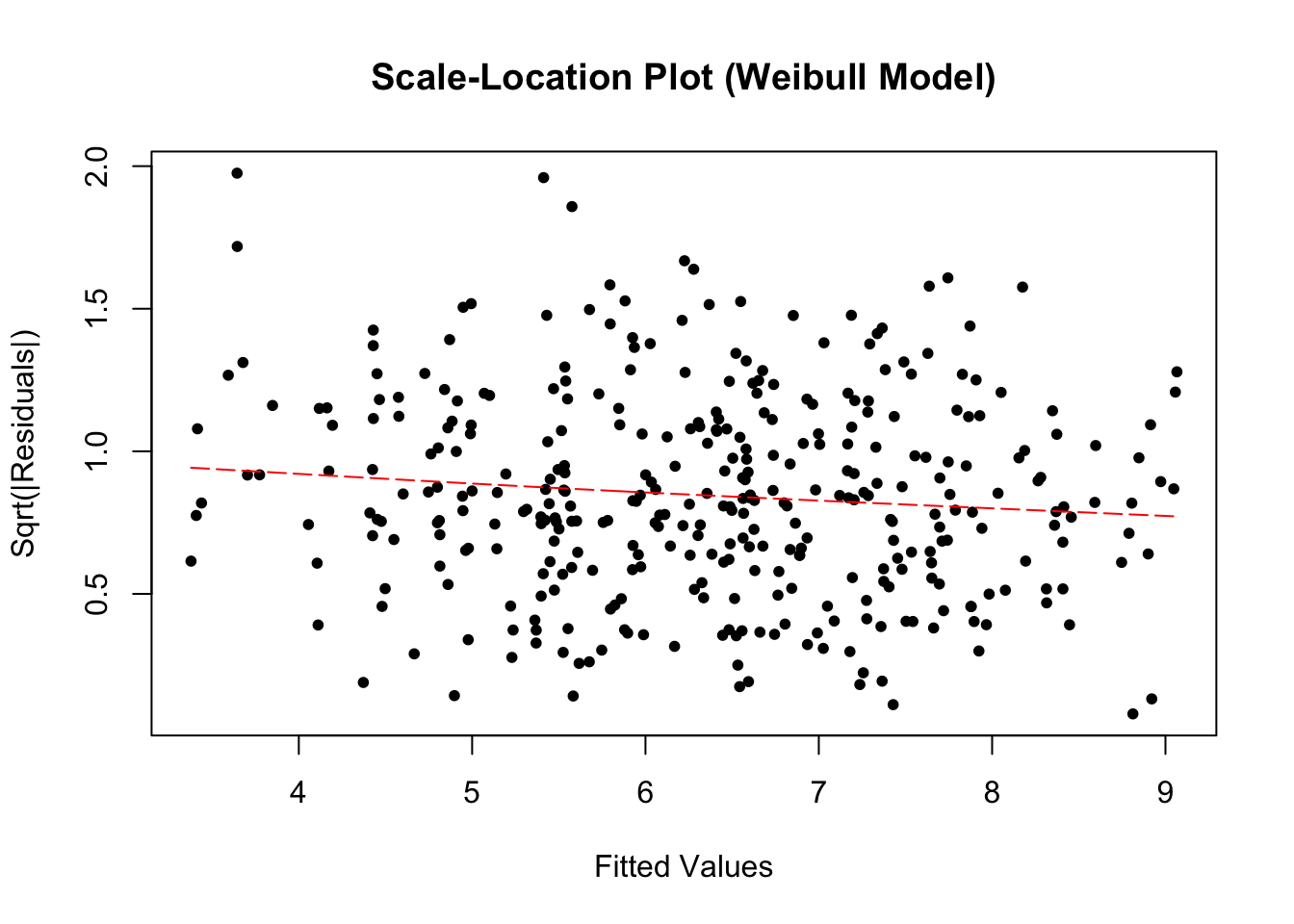
I will show diagnostic plots for this model only but none of the models showed any cause for concern. Note, for a Weibull model, we expect the deviance residuals to be i.i.d.
It is easiest to start with the linear model because the coefficients are easiest to interpret. Aside from the auto-regressive component, each coefficient represents the value in hours to add (or subtract) from the Intercept of 7.44 hours or 07 hours 26 minutes 26 seconds. For example, I should expect my mean sleeping hours to be 7.44 -1.8 during the month of July, or 05 hours 38 minutes 37 seconds (ignoring the standard errors, for simplicity). Similarly, eating cheese for dinner has a mean effect of -1.67. This was the strongest of the four food triggers.
Good job I never eat fondue in the summer!
The Generalized linear model has a slightly different interpretation. We would calculate the linear predictor from the coefficients just the same as with the linear model, but then take the inverse to get the prediction response. As a result, the coefficients have the opposite sign as that given by the linear model coefficients, and the magnitudes are less intuitive to quantify. The base case of month April (alphabetically the first, so set as the reference level by R) and no food triggers, the intercept is \(\frac{1}{0.1311168}\) or 07 hours 26 minutes 26 seconds (exactly the same value as the linear model, which is expected). This predictor grows or shrinks linearly with the coefficients, but multiplicatively on the response scale. This is the equivalent of growing or shrinking the intercept as a starting value by a factor of \(\frac{\beta_0}{\beta_0 + \beta_1 + \beta_2 \ldots}\) where \(\beta_0\) is the Intercept and \(\beta_1 + \beta_2 \ldots\) are the remaining coefficients whose criteria evaluate as true.
In both of the above descriptions, the auto-regressive component adds a multiple of its coefficient value equal to the time sleeping of the day before.
The Weibull model’s coefficients are also used to generate a linear predictor but the relationship of this predictor is even less intuitive than the inverse linked Gamma model. The link function is
where \(\eta = X\beta\), is the linear predictor and \(k\) is the Weibull shape parameter, and it’s log inverse \(\frac{1}{k}\) is returned as Log(scale) in the model summary. We can see from the above that the coefficients are also on the log scale of the prediction response. However, usefully (and unlike the Gamma model), their sign is aligned with their increasing or decreasing effect on the time sleeping response. So, for the base case (month of April and no food triggers), the linear predictor is simply 2.0665712, which exponentiated give us 7.8976967. Log($k$) from the model summary is 1.9393441 and so \(k\) is 6.9541879 and it’s inverse is 0.1437982, which will plug into the equation above. The predicted response is therefore:
which at 07 hours 23 minutes 06 seconds is a little shorter than base case for the linear model and generalized linear model described above.
We can use the base case of month April and no food triggers to investigate the auto-regressive effect quality of sleep the night before.
1
2
3
4
5
## Night before 06 hours 53 minutes 51 seconds -> predicted time 07 hours 14 minutes 26 seconds
## Night before 07 hours 23 minutes 51 seconds -> predicted time 07 hours 11 minutes 43 seconds
## Night before 07 hours 53 minutes 51 seconds -> predicted time 07 hours 09 minutes 00 seconds
## Night before 08 hours 23 minutes 51 seconds -> predicted time 07 hours 06 minutes 19 seconds
## Night before 08 hours 53 minutes 51 seconds -> predicted time 07 hours 03 minutes 38 seconds
We can see that around the base case, \(\pm\) each 30 minutes sleep leads to an inverse (change of sign) change of \(\pm \approx\) 3 minutes. Recall that the linear predictor is on the log scale, so the effect is not linear with the previous night’s sleeping time.
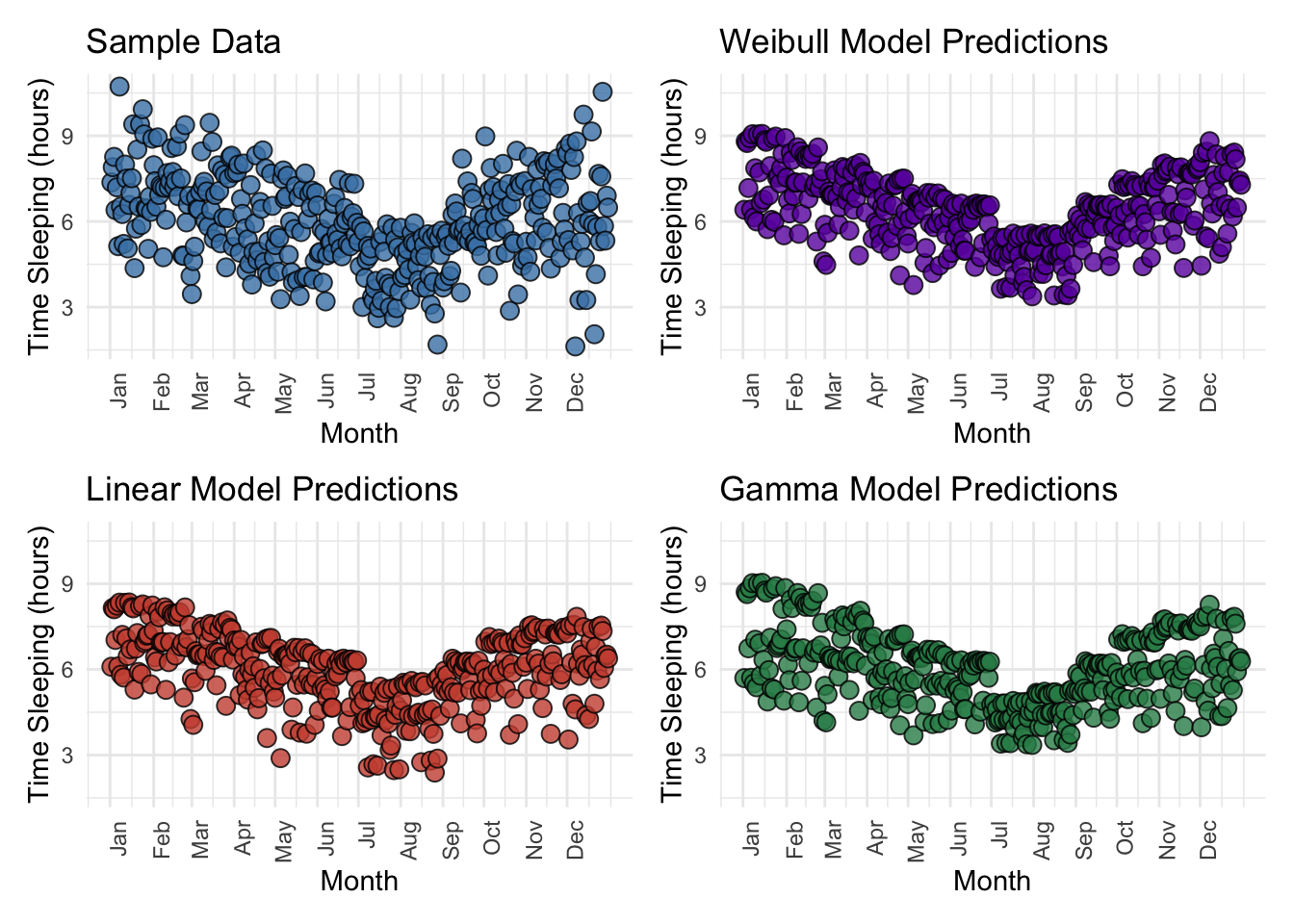
Here I show a visual comparison of the true and predicted values from each model. Not too much to say, except the linear model seems to be biased somewhat toward under-estimating sleeping time.
So far, I’ve diagnosed and intepreted the Weibull model as if it is a linear model, but survival analysis deals with the estimation in terms of a survival function, the probability of surviving (sleeping) up to a point in time \(t\):
$$
S(t) = P(T > t),\ 0 < t < \infty
$$
where, in this case \(T\) is time sleeping. For \(t = 0\), \(S(t) = 1\) and is monotonically decreasing with increasing \(t\). The survival function for a Weibull model is:
Point predictions from such a model are equal to the expected value, of course. However, the Weibull distribution is very flexible, and this point prediction may be far from the most common outcome. On the other hand, the survival curve is useful because it is so easy to estimate the median or a quartile range, for example. This is much easier to understand. On any night with the same conditions, I will sleep this long or shorter/longer 50% of the time. To see the utility of this, we can plot survival curves for various combinations of food triggers at different times of year, and we have an intuitive interpretation as the diminishing chance to still be asleep after a certain length of time has elapsed.
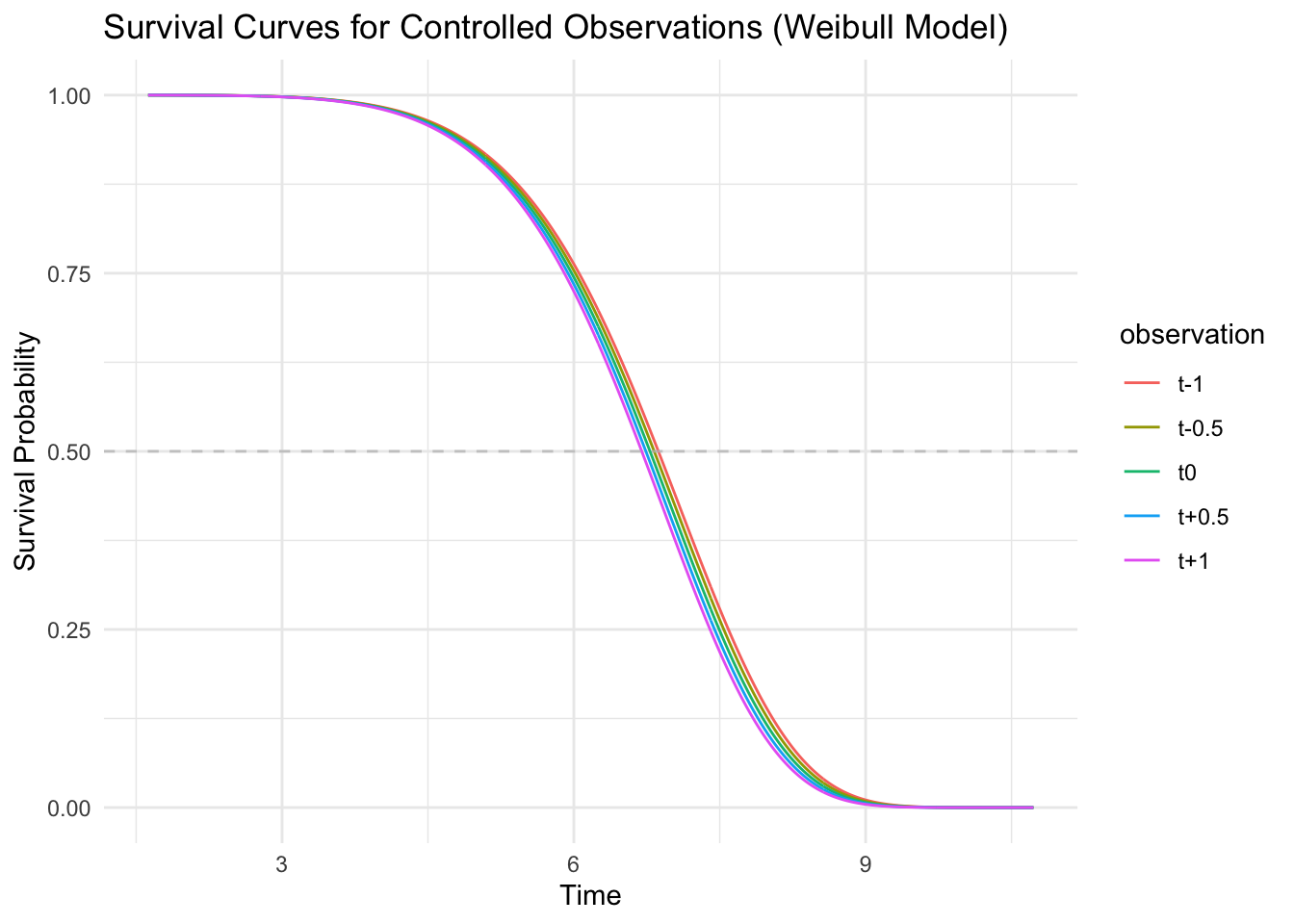
First, I will review the base case \(\pm\) 30 minutes and 1 hour.
1
2
3
4
5
## Night before 06 hours 53 minutes 51 seconds -> predicted median 06 hours 52 minutes 08 seconds
## Night before 07 hours 23 minutes 51 seconds -> predicted median 06 hours 49 minutes 33 seconds
## Night before 07 hours 53 minutes 51 seconds -> predicted median 06 hours 46 minutes 59 seconds
## Night before 08 hours 23 minutes 51 seconds -> predicted median 06 hours 44 minutes 25 seconds
## Night before 08 hours 53 minutes 51 seconds -> predicted median 06 hours 41 minutes 53 seconds
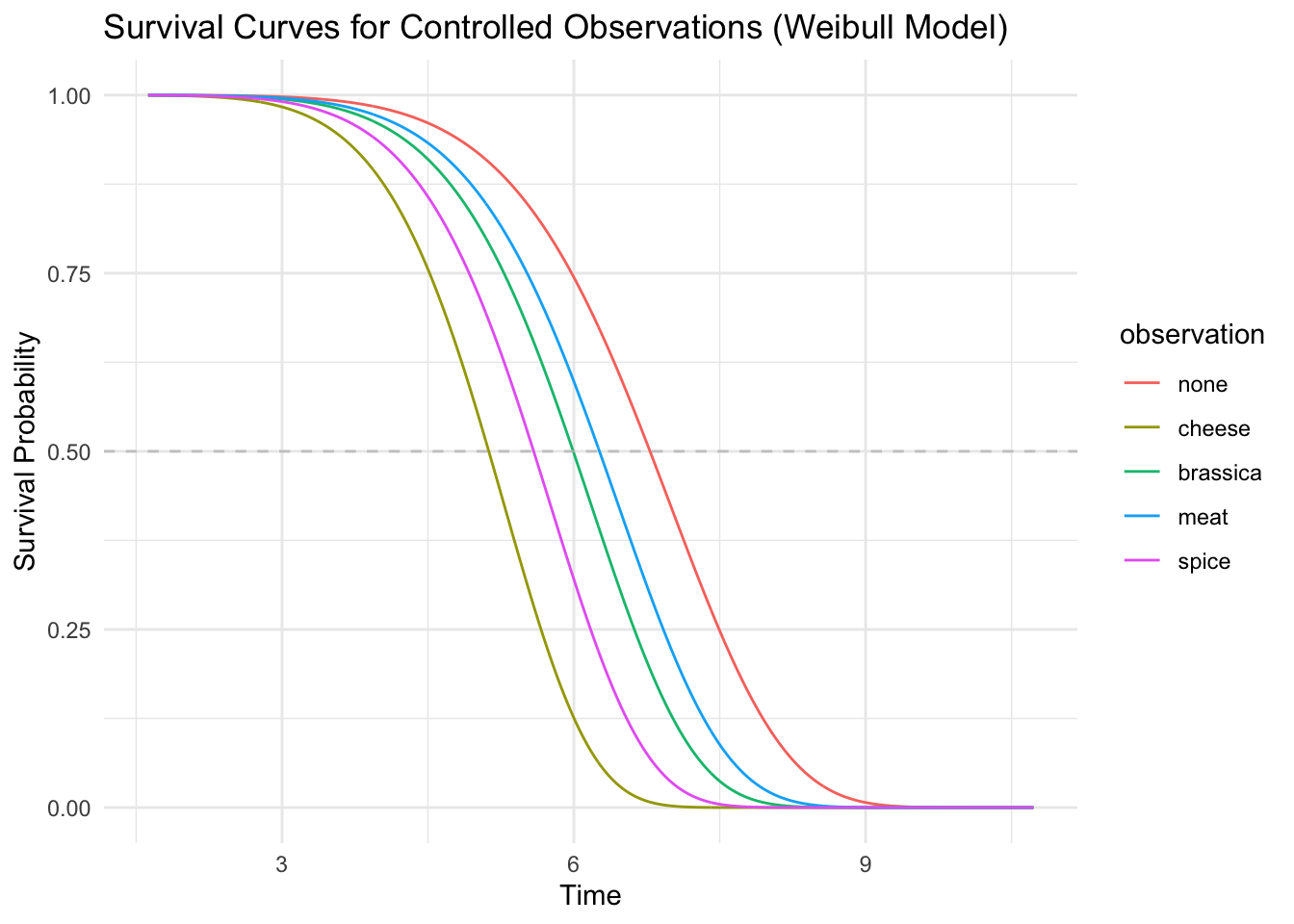
Then we can try the base case with different food triggers:
I am quite shocked at just how pronounced the effect is of these different foods are on my sleep patterns. I have also ascertained that the effect is linear on the log time scale, which I interpret to imply that the effect of combining these foods is diminishing, relative to the hit of taking any one of them for dinner. Cheese is especially bad, which is not suprising as I have a medical lactose intolerance. However, it’s taken until now to really understand the impact that this has had on my quality of life.
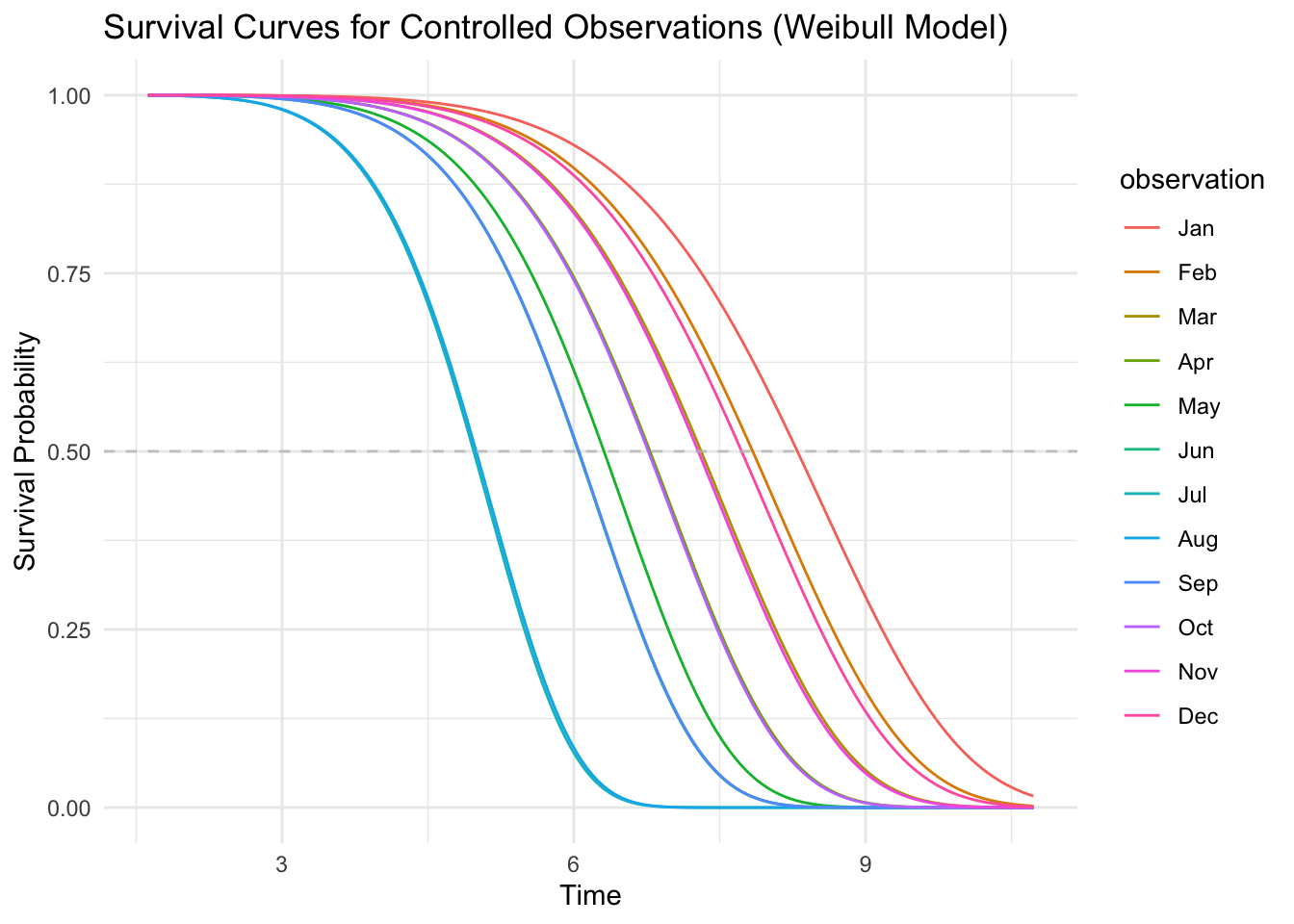
As a final analysis, let’s take a look at seasonal effects, controlling for everything else:
1
2
3
4
5
6
7
8
9
10
11
12
## Month Jan -> predicted median 08 hours 17 minutes 53 seconds
## Month Feb -> predicted median 07 hours 50 minutes 19 seconds
## Month Mar -> predicted median 07 hours 18 minutes 30 seconds
## Month Apr -> predicted median 06 hours 46 minutes 59 seconds
## Month May -> predicted median 06 hours 18 minutes 34 seconds
## Month Jun -> predicted median 06 hours 02 minutes 45 seconds
## Month Jul -> predicted median 04 hours 58 minutes 12 seconds
## Month Aug -> predicted median 04 hours 59 minutes 45 seconds
## Month Sep -> predicted median 06 hours 03 minutes 06 seconds
## Month Oct -> predicted median 06 hours 45 minutes 55 seconds
## Month Nov -> predicted median 07 hours 16 minutes 42 seconds
## Month Dec -> predicted median 07 hours 43 minutes 29 seconds
Here again, it’s a shock to see just how bad things get during the summer months when the hours of darkness are especially short. I should surely invest in a sleep mask.
Having suffered with insomnia my whole life and sometimes been at a loss to know what to do about it, I decided to create a personal dataset with a fitness tracker and a food diary.
I compared and contrasted three regression models, and selected a Weibull regression as the best model. This model had the following characteristics:
The lowest AIC score of the three models.
Was significantly better than the other two models in a likelihood ratio test
Supports regressing on an auto-regressive component, significant because sleep quality the day before affects the following day
Guarantees never to predict a negative number (impossible for this real-world applied scenario)
Has an intuitive interpretation, using survival analysis
I then demonstrated the difference between the point prediction and the survival curve. The survival curve allows me to estimate the median time I would expect to sleep, controlling for different conditions. This is by far the most intuitive reading of the predictor because the linear predictor is on the log time scale and is further transformed with a gamma function term to be arithmetically correct, rendering the relationship between the coefficients and the prediction harder to reason about.
ad_test_normal<-ad.test(dframe$time_sleeping,pnorm,mean=mean(dframe$time_sleeping),sd=sd(dframe$time_sleeping))print(ad_test_normal)qqnorm(dframe$time_sleeping,main="Q-Q Plot for Normal Distribution")qqline(dframe$time_sleeping,col="red")
wb_df<-wb_model$df.residualwb_loglik<-wb_model$loglik[2]lm_df<-lm_model$df.residuallm_loglik<-logLik(lm_model)[1]glm_df<-glm_model$df.residualglm_loglik<-logLik(glm_model)[1]wb_lm_lrt_stat<-2*(wb_loglik-lm_loglik)wb_glm_lrt_stat<-2*(wb_loglik-glm_loglik)lm_glm_lrt_stat<-2*(lm_loglik-glm_loglik)wb_lm_df_diff<-abs(wb_df-lm_df)wb_glm_df_diff<-abs(wb_df-glm_df)lm_glm_df_diff<-abs(lm_df-glm_df)wb_lm_p_value<-pchisq(wb_lm_lrt_stat,df=wb_lm_df_diff,lower.tail=FALSE)wb_glm_p_value<-pchisq(wb_glm_lrt_stat,df=wb_glm_df_diff,lower.tail=FALSE)lm_glm_p_value<-pchisq(lm_glm_lrt_stat,df=lm_glm_df_diff,lower.tail=FALSE)noquote(sprintf("WB > LM, Likelihood Ratio Test Statistic: %.3f, p-value: %.3f",wb_lm_lrt_stat,wb_lm_p_value))noquote(sprintf("WB > GLM, Likelihood Ratio Test Statistic: %.3f, p-value: %.3f",wb_glm_lrt_stat,wb_glm_p_value))noquote(sprintf("LM > GLM, Likelihood Ratio Test Statistic: %.3f, p-value: %.3f",lm_glm_lrt_stat,lm_glm_p_value))
1
2
3
4
5
6
7
8
9
10
11
wb_fitted<-predict(wb_model,type="response")wb_residuals<-residuals(wb_model,type="deviance")plot(wb_fitted,wb_residuals,xlab="Fitted Values",ylab="Deviance Residuals",main="Residuals vs Fitted Values (Weibull Model)",pch=20)spline_fit<-smooth.spline(wb_fitted,wb_residuals)# Add the fitted spline line to the plotlines(spline_fit,col="red",lwd=1,lty=5)
1
2
3
4
5
6
7
8
9
sqrt_abs_residuals<-sqrt(abs(wb_residuals))plot(wb_fitted,sqrt_abs_residuals,xlab="Fitted Values",ylab="Sqrt(|Residuals|)",main="Scale-Location Plot (Weibull Model)",pch=20)spline_fit<-smooth.spline(wb_fitted,sqrt_abs_residuals)# Add the fitted spline line to the plotlines(spline_fit,col="red",lwd=1,lty=5)
1
2
qqnorm(wb_residuals,main="Q-Q Plot of Deviance Residuals (Weibull Model)")qqline(wb_residuals,col="red")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
ar_1_pm<-c(-1.0,-0.5,0.0,0.5,1.0)sleep_night_before<-exp(wb_model[["coefficients"]][["(Intercept)"]])+ar_1_pmnewdata_base_case=data.frame(month="Apr",ar_1=sleep_night_before,cheese=FALSE,brassica=FALSE,meat=FALSE,spice=FALSE)base_predicted_sleep<-predict(wb_model,newdata=newdata_base_case,type="response")for(iinseq_along(sleep_night_before)){cat(noquote(sprintf("Night before %s -> predicted time %s\n",convert_hms(sleep_night_before[i]),convert_hms(base_predicted_sleep[i]))))}
result_frame=cbind(time_sleeping=dframe$time_sleeping,wb_model_preds=predict(wb_model,type="response"),lm_model_preds=predict(lm_model,type="response"),glm_model_preds=predict(glm_model,type="response"))y_min=min(result_frame)y_max=max(result_frame)result_frame<-cbind(result_frame,trend=dframe$trend)plot_function<-function(series,series_name,fill,color){ggplot(data=result_frame,aes(x=trend,y={{series}}))+geom_point(shape=21,fill=fill,color=color,size=3,alpha=0.8)+labs(title=series_name,x="Month",y="Time Sleeping (hours)")+scale_x_continuous(breaks=month_positions,labels=month_name)+scale_y_continuous(limits=c(y_min,y_max))+theme_minimal()+theme(axis.text.x=element_text(angle=90,hjust=1))}p1<-plot_function(time_sleeping,"Sample Data","steelblue","black")p2<-plot_function(wb_model_preds,"Weibull Model Predictions","#6A0DAD","black")p3<-plot_function(lm_model_preds,"Linear Model Predictions","#CC503E","black")p4<-plot_function(glm_model_preds,"Gamma Model Predictions","#2E8B57","black")# Combine plots in a 2x2 grid using patchwork(p1|p2)/(p3|p4)
shape<-1/wb_model$scalegranularity<-1000paste_plus<-function(num){ifelse(num>0,paste0("+",num),num)}base_case_names<-paste0("t",paste_plus(ar_1_pm))get_probs<-function(linear_predictor,case_names){scale<-exp(linear_predictor)# Scale parameter for each observationtime<-seq(min(dframe$time_sleeping),max(dframe$time_sleeping),length.out=granularity)# smooth curve over complete time rangesurv_probs_tibble<-tibble(time=time)for(iinseq_along(scale)){surv_probs_tibble<-surv_probs_tibble%>%mutate(!!case_names[i]:=exp(-(time/scale[i])^shape))}return(surv_probs_tibble)}surv_plot_func<-function(surv_probs){# Reshape the data to long format for ggplotsurv_probs_long<-surv_probs%>%pivot_longer(cols=-time,names_to="observation",values_to="survival_prob")surv_probs_long$observation<-factor(surv_probs_long$observation,levels=unique(surv_probs_long$observation))# Create the ggplot objectp<-ggplot(surv_probs_long,aes(x=time,y=survival_prob,color=observation))+geom_line()+geom_hline(yintercept=0.5,linetype="dashed",color="grey",alpha=0.75)+labs(x="Time",y="Survival Probability",title="Survival Curves for Controlled Observations (Weibull Model)")+theme_minimal()# Minimal theme for a clean lookreturn(p)}get_median_survival<-function(scale){# expecting linear predictor on log scaleexp(scale)*(log(2))^(1/shape)}
1
2
3
4
5
6
7
8
linear_predictor<-predict(wb_model,newdata=newdata_base_case,type="lp")surv_plot_func(get_probs(linear_predictor,base_case_names))median_surv<-get_median_survival(linear_predictor)names(median_surv)<-base_case_namesfor(iinseq_along(sleep_night_before)){cat(noquote(sprintf("Night before %s -> predicted median %s\n",convert_hms(sleep_night_before[i]),convert_hms(median_surv[i]))))}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
newdata_food_trigger_cases=data.frame(month="Apr",ar_1=exp(wb_model[["coefficients"]][["(Intercept)"]]),cheese=c(FALSE,TRUE,FALSE,FALSE,FALSE),brassica=c(FALSE,FALSE,TRUE,FALSE,FALSE),meat=c(FALSE,FALSE,FALSE,TRUE,FALSE),spice=c(FALSE,FALSE,FALSE,FALSE,TRUE))food_trigger_case_names<-c("none","cheese","brassica","meat","spice")linear_predictor<-predict(wb_model,newdata=newdata_food_trigger_cases,type="lp")surv_plot_func(get_probs(linear_predictor,food_trigger_case_names))median_surv<-get_median_survival(linear_predictor)names(median_surv)<-food_trigger_case_namesfor(iinseq_along(sleep_night_before)){cat(noquote(sprintf("Food trigger %s -> predicted median %s\n",food_trigger_case_names[i],convert_hms(median_surv[i]))))}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
newdata_food_trigger_cases=data.frame(month=month_name,ar_1=exp(wb_model[["coefficients"]][["(Intercept)"]]),cheese=FALSE,brassica=FALSE,meat=FALSE,spice=FALSE)linear_predictor<-predict(wb_model,newdata=newdata_food_trigger_cases,type="lp")surv_plot_func(get_probs(linear_predictor,month_name))median_surv<-get_median_survival(linear_predictor)names(median_surv)<-month_namefor(iinseq_along(month_name)){cat(noquote(sprintf("Month %s -> predicted median %s\n",month_name[i],convert_hms(median_surv[i]))))}