Analysing SaaS Trial to Subscriber Conversions - Part 2 - Comparing Groups with Stratified Analysis
Last Updated:
Table of Contents
Introduction #
You can read the Series Introduction here
In the previous post, we saw how a Survival curve can be reframed as a Conversion Momentum Curve (CMC), giving us a way to esitmate when (counting in days from the start of a free trial period) we will reach conversion rate milestone of e.g. 5%, 10%, or 15% of free trial users. This is useful information because anything we can do to shorten the free trial period for our SaaS product offsets our fixed operating costs with new revenue.
We saw that our overall CMC looks like this:
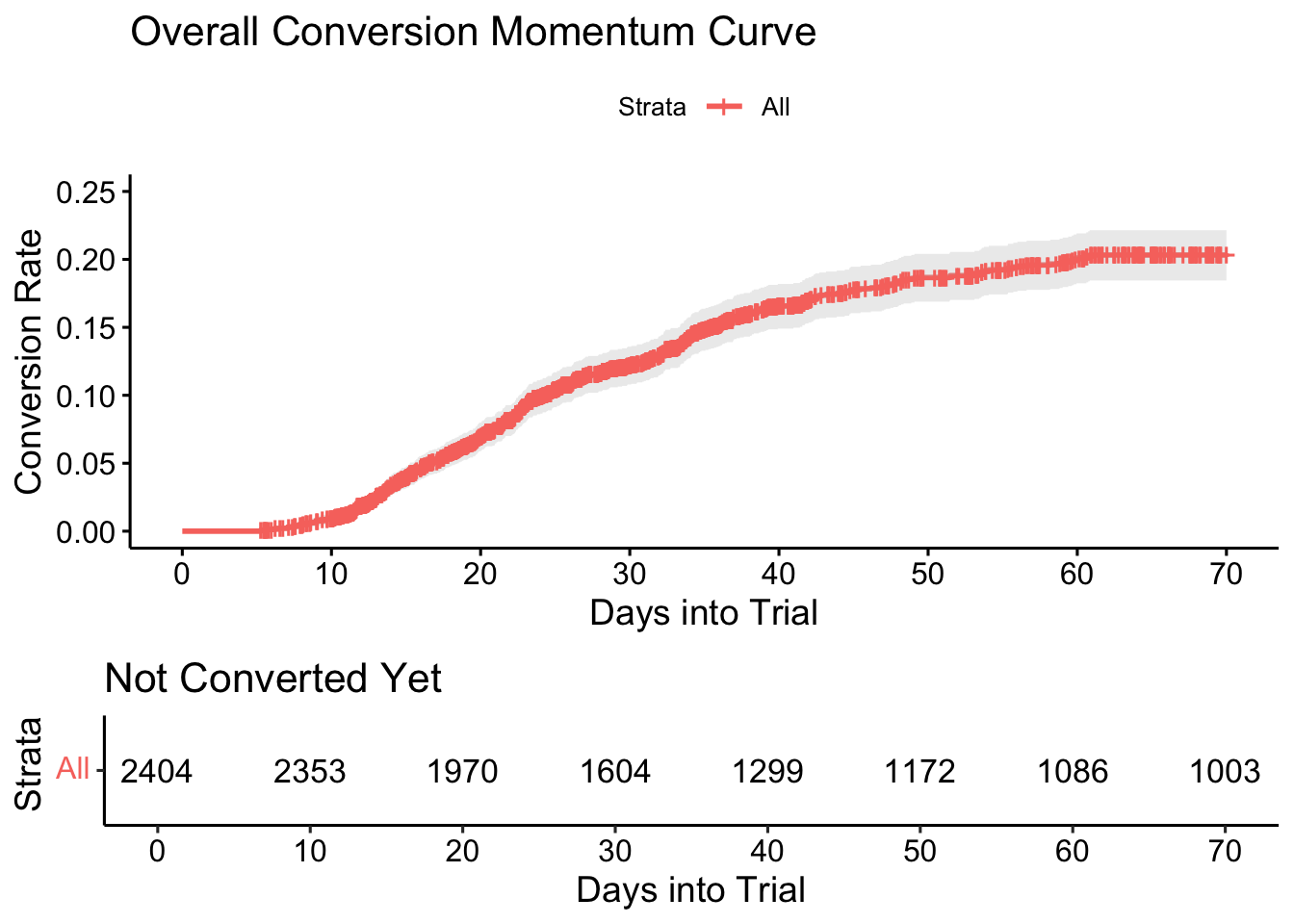
This curve shows us the cumulative conversion rate at time \(t\) (days) and gives us a sense of how the conversion rate evolves over the time spent in the free-trial period.
In this follow-up post, we use the standard KM-estimator method to estimate a non-parametric CMC and analyse differences between groups according to industry, acquisition channel, and geographic sales region. In Survival Analysis, this is called stratified estimation and, with certain assumptions, we can make inferences and hypothesis tests about the differences.
We consider customer invariant data that is already decided at the start of the free trial period that we cannot intervene on. We can only react to it. We track many other customer variables, such as the frequency with which they login and the customer success calls that we conduct with them. These types of variables are time dependent, just like the conversion event itself. The time they take place can have a profound effect on increasing or decreasing the likelihood of conversion. This requires a different analysis, which we won’t cover in this post. Look out for the next one if you are interested.
Industry Verticals #
We also saw that there were some apparent differences in the raw numbers for the two main industry verticals in which we operate: Homeware and Industrial Components
| industry | n | convs | conv_rate | med_time_all | med_time_conv |
|---|---|---|---|---|---|
| homeware | 1589 | 296 | 18.6 | 44.8 | 22.7 |
| industrial | 815 | 94 | 11.5 | 49.7 | 22.5 |
Let’s see how these differences manifest in the CMC analysis:
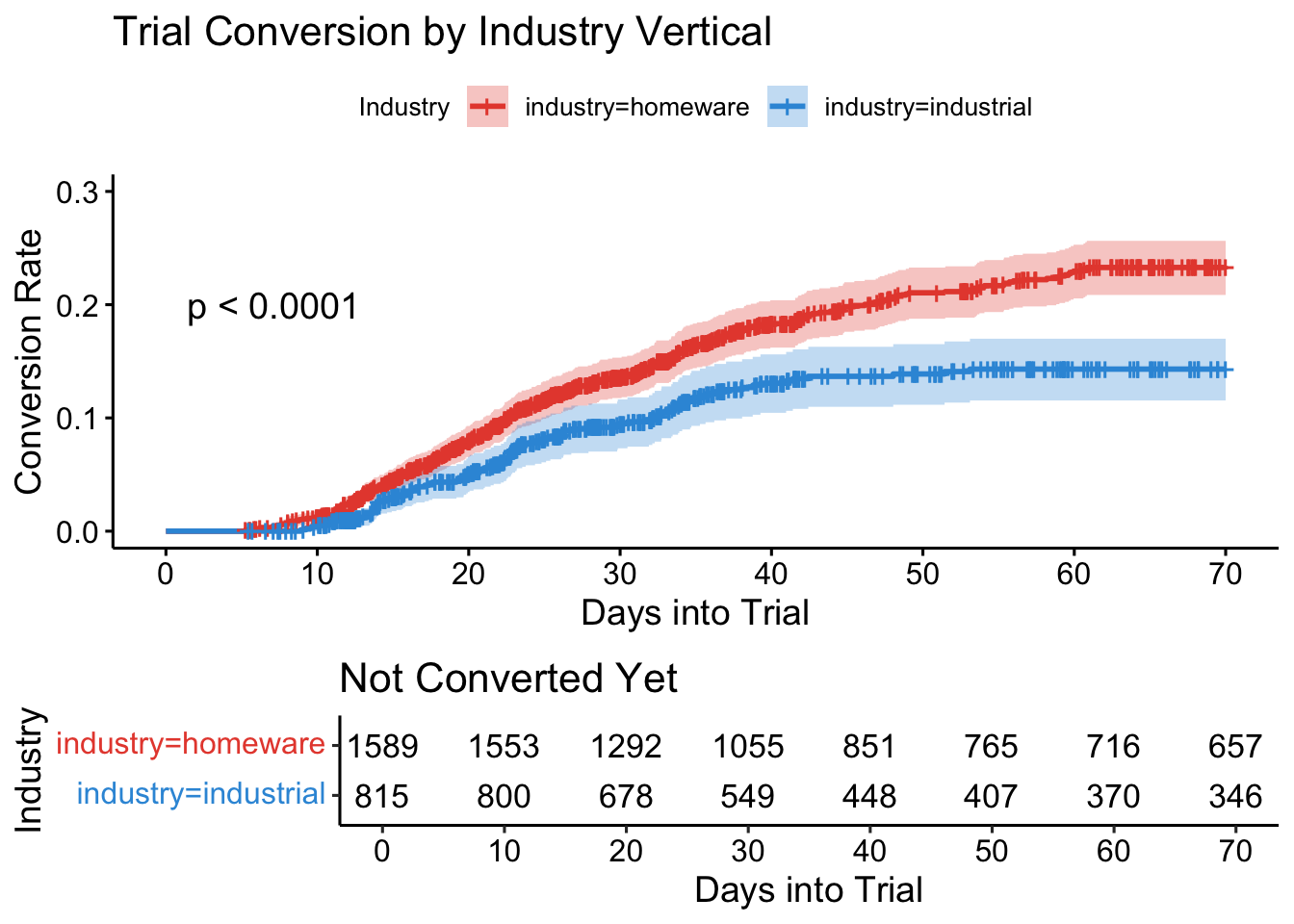
This chart gives us a very clear indication that these two curves are different. Very early on, the event lines separate and the confidence intervals no longer overlap. The charting code runs a Log-rank test in the background and p-value of this test is displayed. For completeness, we can also show the full Log-rank test table, which is based on a \(\chi^2\) test statistic:
|
|
Acquisition Channels #
Previously, we also so some crucial differences in the conversion rates per customer acquisition channel. It is essential for us to analyse this more deeply and understand how to optimise our marketing spend.
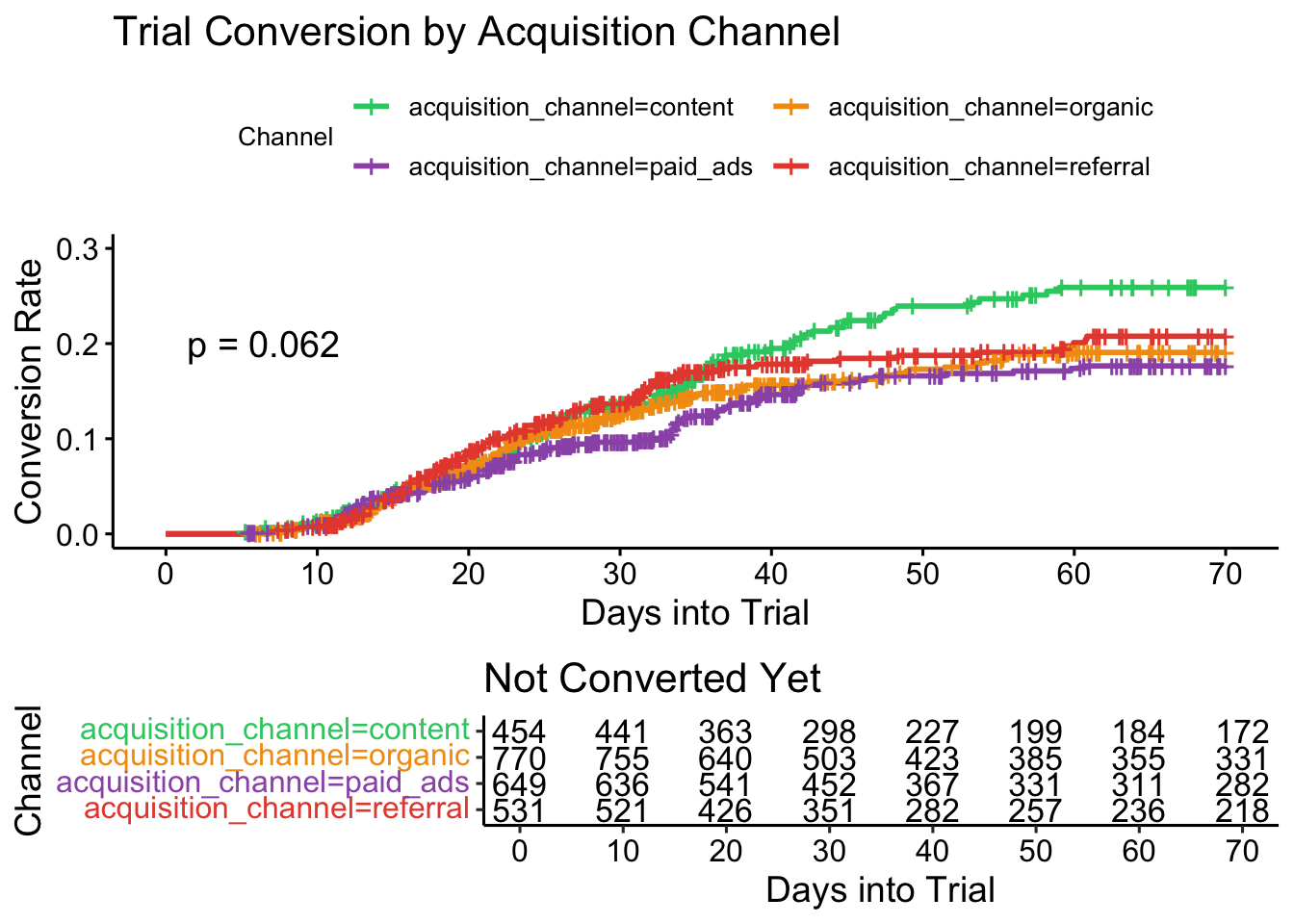
The confidence intervals have been omitted because there is a lot of overlap, which is somewhat messy with four overlapping curves.
|
|
The results here are rather nuanced. With a p-value of 0.062, the evidence against the null hypothesis of no difference between the curves is borderline or weak. We also see the event lines crossing in some places, indicating either no difference, or that an assumption of constant proportion between the hazard rates over time is violated.
Nevertheless, we can see visually that the content channel does diverge from the other three more dramatically when \(t>40\), which supports what we saw in the raw numbers. In a situation like this, it can be more valuable to run a pairwise comparisons test.
|
|
These results suggest that the differences between content vs paid ads and content vs organic channels are significant.
Industry and Channel Interactions #
We can, of course cross-tabulate and stratify on both items to see differences in channel performance across vertical.
|
|
The summary table in the previous post (reproduced here) showed some really obvious differences for the nested results and we had a rational business explanation for this situation: Paid search and referrals do not penetrate well to the right kind of customers in the Industry vertical, who seem to be more intentional in their search for our product.
Let’s flip back to a traditional orientation of the survival curve to understand the impact of this on our operations.
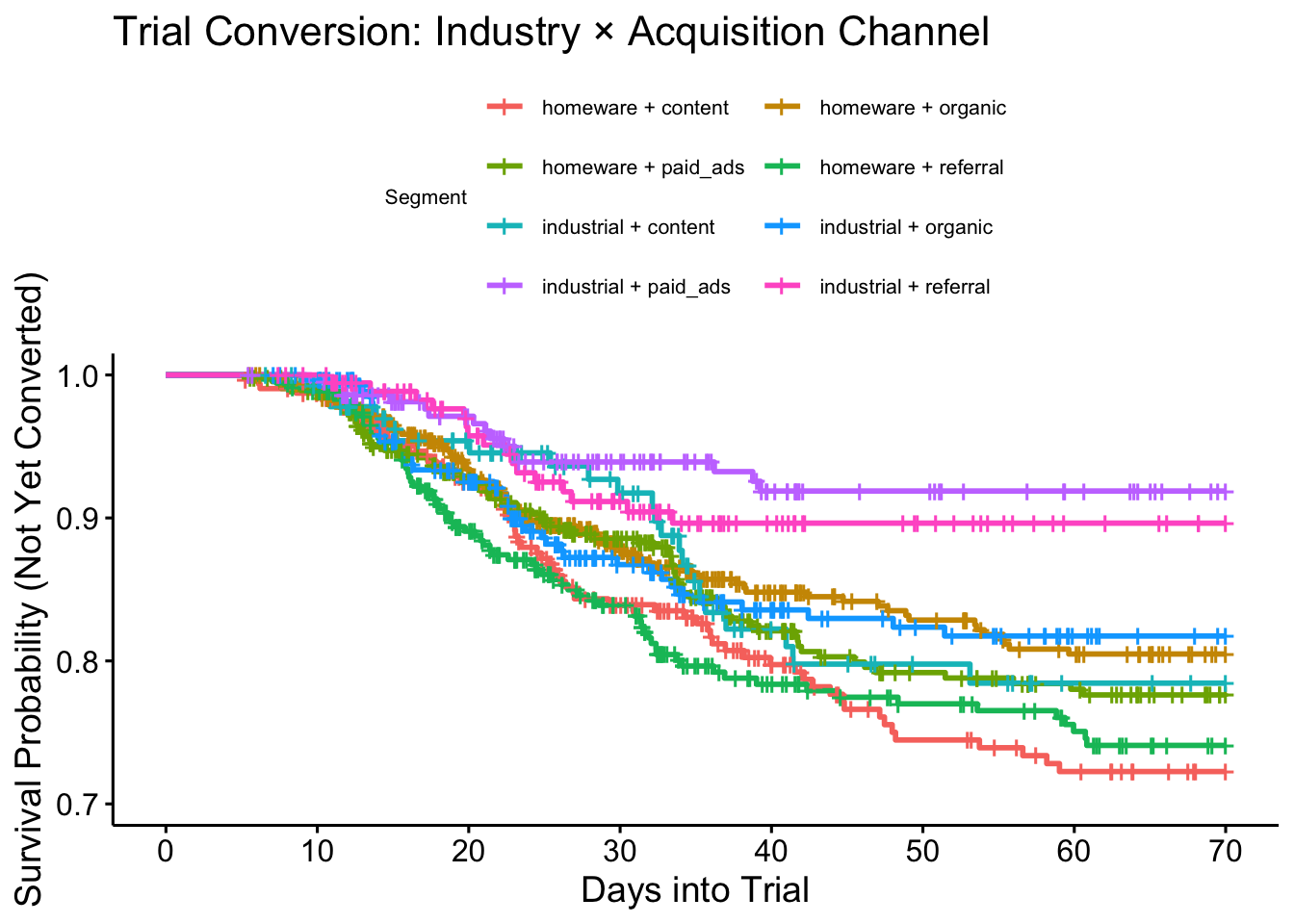
Here we see the conversions for referrals end after around \(t>30\) and for paid search after \(t>40\). The event line flattens out entirely. With this knowledge, we can adjust our offer to customers acquired through these channels and shorten the free trial period, cutting these operating costs much sooner.
Another perspective that we looked at in the previous post was conversion rate milestones. That is, an estimate of the free-trial period that will yield a given conversion rate. This is an adapation of the median survival time to use different quantiles. For example, the 0.1 quantile gives the number of days at which we still have 90% of the trial users unconverted. NA shows where the population never drops below this level.
| industry | acquisition_channel | time_to_10pct_conversion |
|---|---|---|
| homeware | content | 22.8 |
| homeware | organic | 23.8 |
| homeware | paid_ads | 24.8 |
| homeware | referral | 18.8 |
| industrial | content | 32.3 |
| industrial | organic | 22.8 |
| industrial | paid_ads | NA |
| industrial | referral | 33.5 |
In the above table we can see that the content marketing channel in the industrial vertical doesn’t look any better than the referral channel but we know this is not the case from the survival curve. In fact these two curves cross after the 30 day mark, demonstrating very different behaviours with many more customers converting after a longer period in trial.
We can also consider flipping this milestone to an estimate of the conversion rate or proportion of unconverted (survival) after specific periods in free-trial. This is useful to check how much value is left “on the table” when we end the trial periods too early.
| industry | acquisition_channel | day_14_survival | day_30_survival | day_45_survival |
|---|---|---|---|---|
| homeware | content | 0.97 | 0.84 | 0.77 |
| homeware | organic | 0.97 | 0.88 | 0.84 |
| homeware | paid_ads | 0.95 | 0.89 | 0.80 |
| homeware | referral | 0.96 | 0.84 | 0.77 |
| industrial | content | 0.97 | 0.92 | 0.80 |
| industrial | organic | 0.96 | 0.87 | 0.83 |
| industrial | paid_ads | 0.99 | 0.94 | 0.92 |
| industrial | referral | 0.99 | 0.91 | 0.90 |
Here we see that waiting until 45 days delivers an additional 10% conversion for this channel. This delivers very significant business value!
Geographic Sales Region #
Let’s take a look at the last customer invariant, which is of limited interest because there aren’t many levers we can pull around the way cultural and local business factors affect purchasing behaviours.
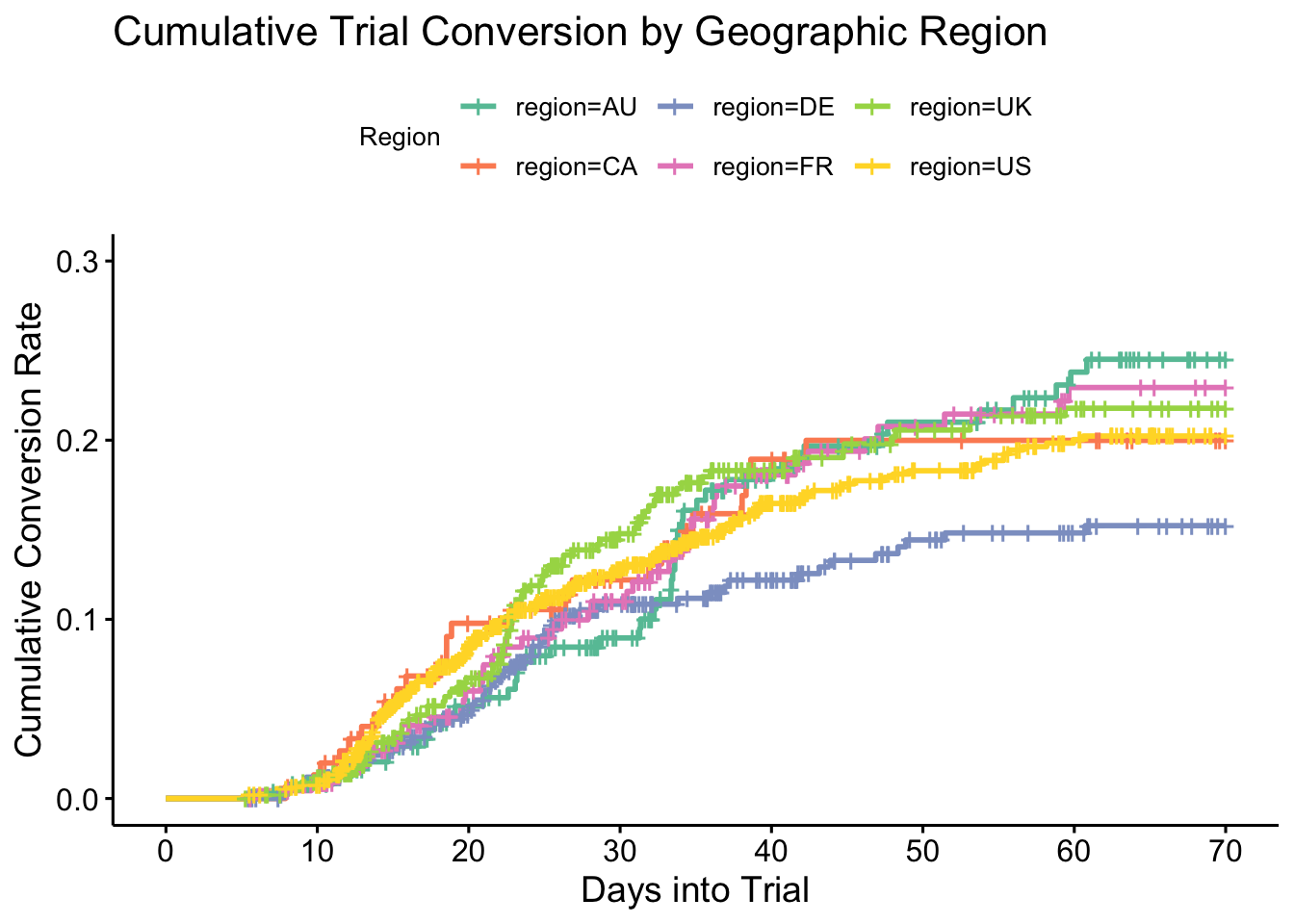
We see most of the regions are pretty similar, other than the German (DE) market which begins to lag behind the others after 30 days. Australia is also interesting because it picks up pace around that time and crosses (overtakes) all the other regions conversion rates to take the top spot by the end of the ten week cut off. People in this market really take their time to become familiar with the product for the first month or so and do not rush into making a decision but the product is quite popular in the end.
Let’s run the pairwise Log-rank tests to look for significant differences.
|
|
We see that all the comparisons with DE are significantly different when considering the non-adjusted p-values but not when the tests are adjusted for the multiple comparisons. No other significant differences are found. The insights gained may be used to modify incentives within the German sales process.
Customer Engagement Level #
As mentioned, this variable represents the initial feature selected by the customer during their initial onboarding. This is an ordinal factor with four levels because we don’t go so far as analyzing which of the four main features are activated. In fact, we simply convert this to a binary factor for Low Engagement (< 3 features) or High Engagement (>= features).
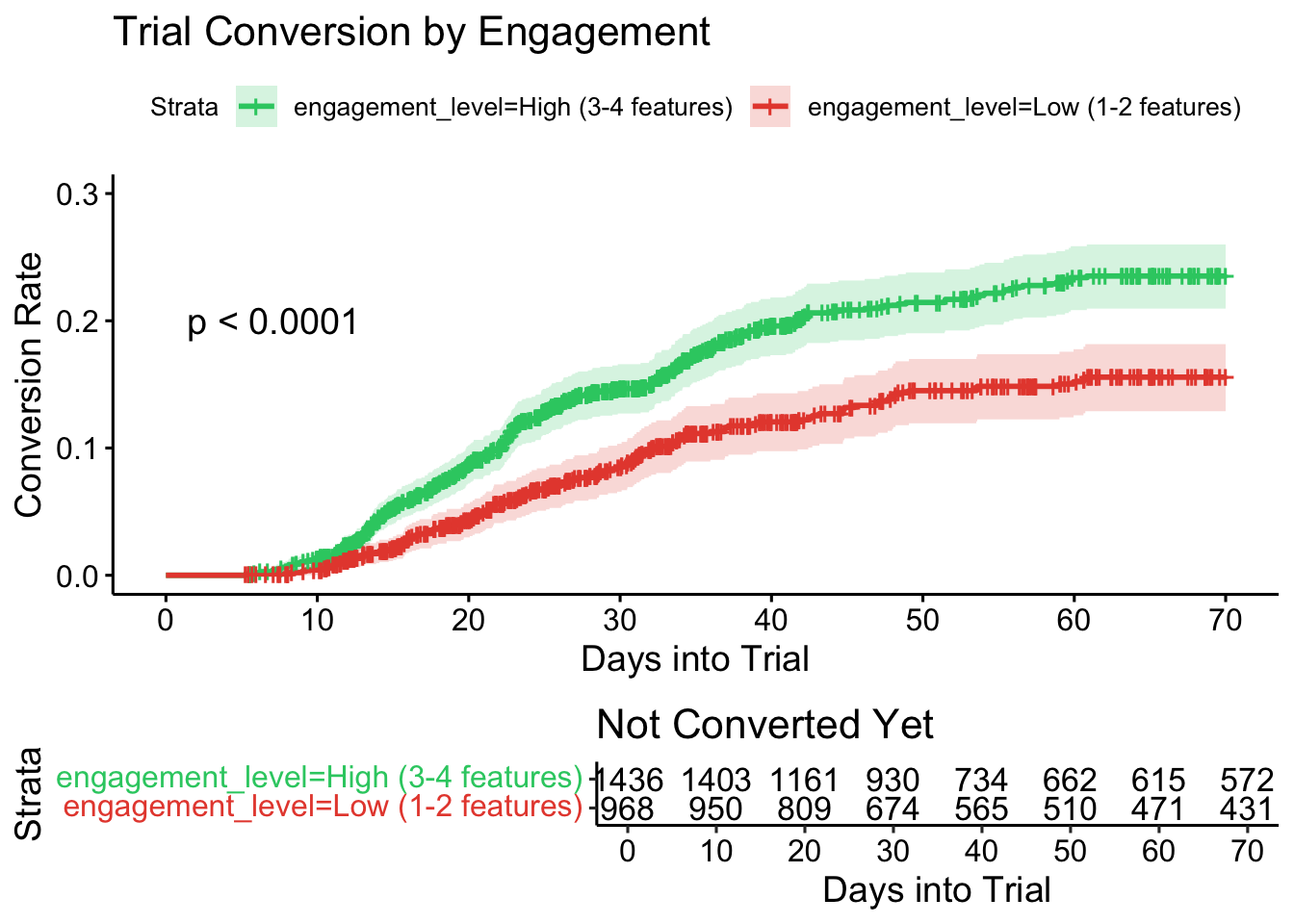
We see that the customers with a high initial engagement have a significantly higher conversion rate, certainly from around day 15 onward. Note that we cannot say with any certainty what the causal direction is. Are these customers already interested in all the features and are therefore more likely to convert, or does early exposure to all the feature convince them. It is not within the capability of this type of analysis to say with any certainty.
The Log-rank test result is also shown.
|
|
Summary and Conclusion #
In this post, we used the KM-Estimator to estimate a “flipped” survival curve, effectively \(1-S(t)\). This is more intuitive when discussing cumulative free-trial conversions. We carried out the technique to stratify our curves by multipled customer invariant data. These are factors that are already determined before the trial and won’t change, such as the geographich sales region and the customer acquisition channel.
We used a few additional techniques to estimate milestone quantiles: by when will we achieve a certain conversion rate? how much does the conversion rate change between two fixed time points, such as 30 days and 45 days.
We used the Log-rank test (adjusting for multiple comparisons if necessary) to assess statistical significance between the strata.
Over all, with this very straightforward analysis, we were able to gain a lot of business insights that have the potential to reduce operating costs and boost conversions in certain markets.