Statistical Learning for Heart Disease Diagnosis
Last Updated:Table of Contents
Author’s Note (October 2020): In preparation for work on my published research paper Ada-WHIPS: explaining AdaBoost classification with applications in the health sciences, I wanted to develop some familiarity with medical statistics and diagnostic tools. I decided to take a fairly well-known medical data set and try something different. Instead of performing a straightforward classification model training as would be typical, I took a deep exploratory dive. My intention was to see if I could tease out some intuition as to what were the predictive patterns in the data. The exercise evolved into a potential approach to developing a statistical diagnostic tool, for similarly distributed data. My original report is reproduced below.
Advanced Exploratory Analysis of the UCI Heart Data #
Introduction #
We will conduct an analysis of the UCI Machine Learning Repository heart data set. This data set is often used for demonstrating classification methods. The target variable is usually AtheroscleroticHDisease, which indicates the presence or absence of pathologies of the blood vessels that supply the heart muscle itself. We will do something slightly different here and demonstrate several unsupervised machine learning methods to perform a thorough exploratory analysis. Exploratory analysis is essential for any serious data analytic work in order to develop an intuition about the data, identify the most important independent variables and determine the most appropriate confirmatory and hypothesis tests.
Note, we defer printing the source code until the end of the document, except where we have modified the data. In that case, the code is shown so the reader can understand the actions in context
Research Questions #
- Using descriptive statistics, can we identify patterns among the independent variables?
- Can we use unsupervised learning techniques to deepen our understanding of patterns and relationships in the data?
Analytic Strategy #
We will proceed in two phases:
- An initial exploratory analysis with descriptive statistics:
- to assess the data quality and perform any necessary cleansing.
- to develop an intiution of the distributions and interactions between variables
- this phase will comprise of visual analytics with density plots, box plots, fourfold plots and mosaic plots.
- A comparison of various unsupervised learning methods:
- matrix decomposition methods: PCA and Correspondence Analysis.
- clustering methods, including hierarchical and distance based methods.
- demonstrate any link between clustering and dimension reduction
- finally, compare cluster membership with the known target variable; is there alignment and could cluster membership be an indicator of the presence of heart disease in an individual in the data set?
Note, this is a little different then a typical classification model training. Rather than performing a train/test split, we simply exclude the target variable until after conducting the unsupervised learning techniques.
Initial Exploratory Analysis #
The data dictionary provides the following information:
| name | type | notes |
|---|---|---|
| AtheroscleroticHDisease | factor | Presence of heart disease |
| Age | integer | Age in years |
| Sex | factor | The two accepted levels at the time of data collection |
| ChestPain | factor | Presence/type of chest pain |
| RestBP | integer | Resting blood pressure mm Hg |
| Chol | integer | Serum cholesterol mg/dl |
| Fbs | factor | Fasting blood sugar |
| RestECG | factor | Resting electrocardiograph results |
| MaxHR | integer | Maximum heart rate during exercise |
| ExAng | factor | Exercise induced angina |
| Oldpeak | factor | ST depression exercise relative to rest |
| Slope | factor | Slope of peak ST exercise segment |
| Ca | small integer | Number of major vessels under fluoroscopy |
| Thal | factor | No description given |
The data is imported from a csv file. There are 303 rows and 15 columns. Below is the head and summary.
|
|
|
|
Data Cleansing - First Pass #
There are several obvious problems with the raw data set. X is an index number column and should be removed. AtheroscleroticHDisease is too much to type, so we will change the name. Several variables are coded as numeric but are factors; Sex, for example. The documentation here is informative and guides the following corrections.
|
|
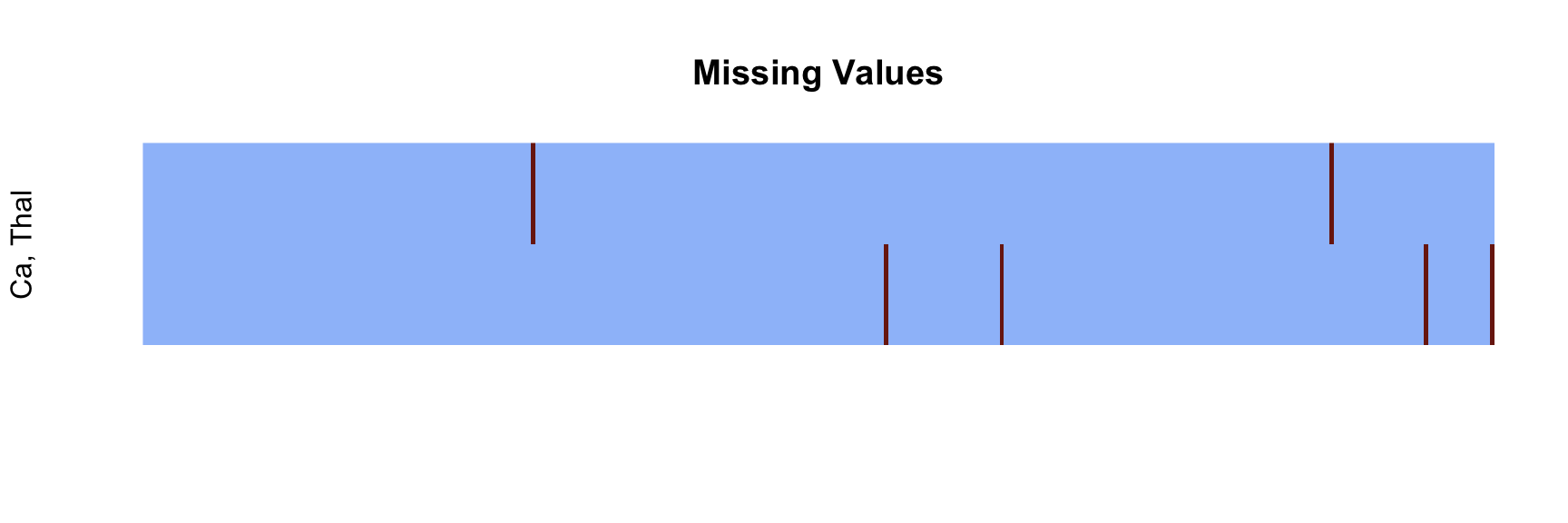
Identify Missing Values #
There is a very small number of missing values, which we would like to impute based on row-wise information. The figure demonstrates that there are no instances that share missingness in both the variables involved. The non-parametric nearest neighbours imputation is a reasonable choice, as it makes no assumptions about the data. This will be executed shortly.
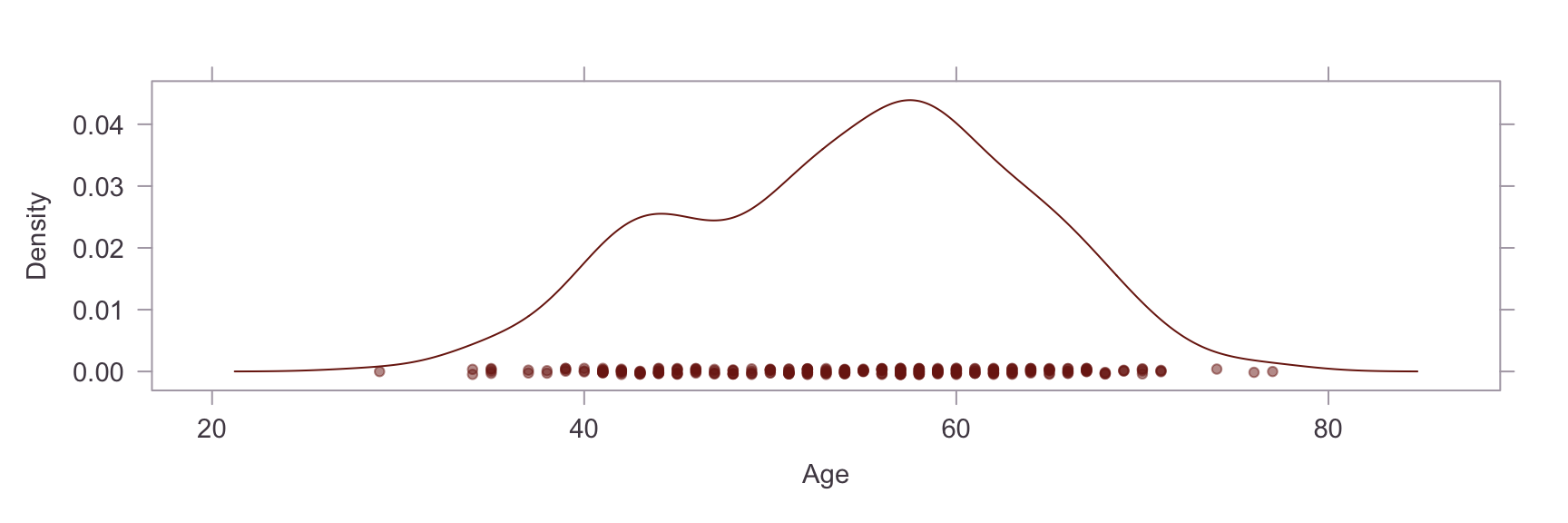
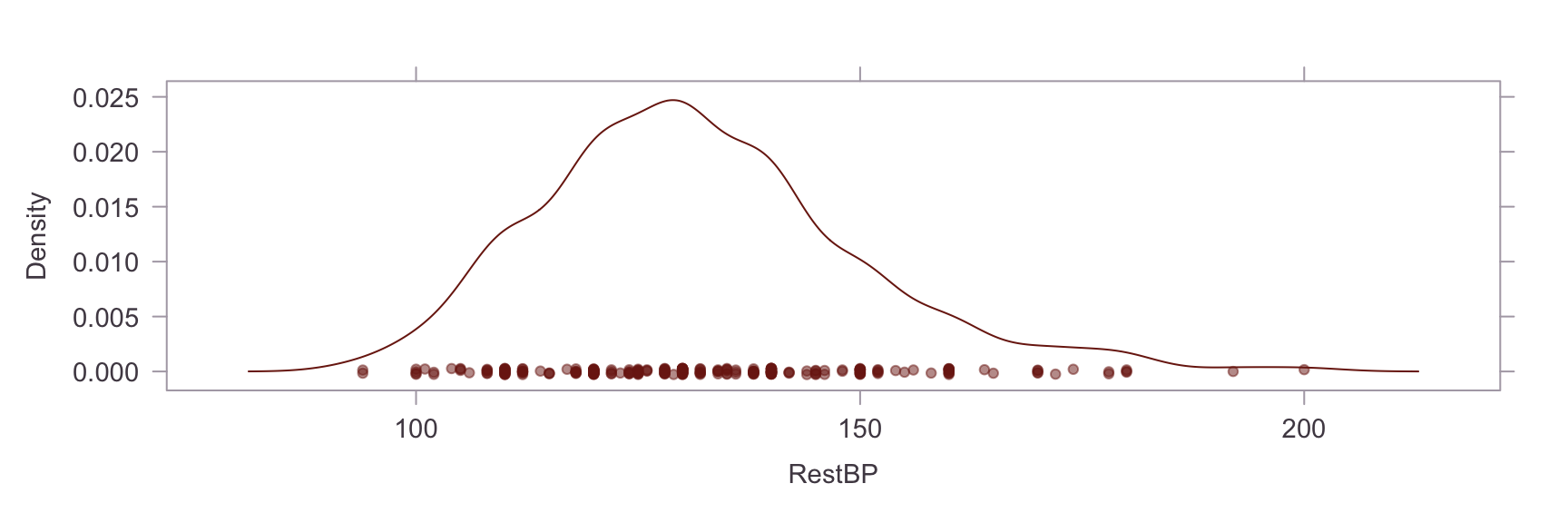
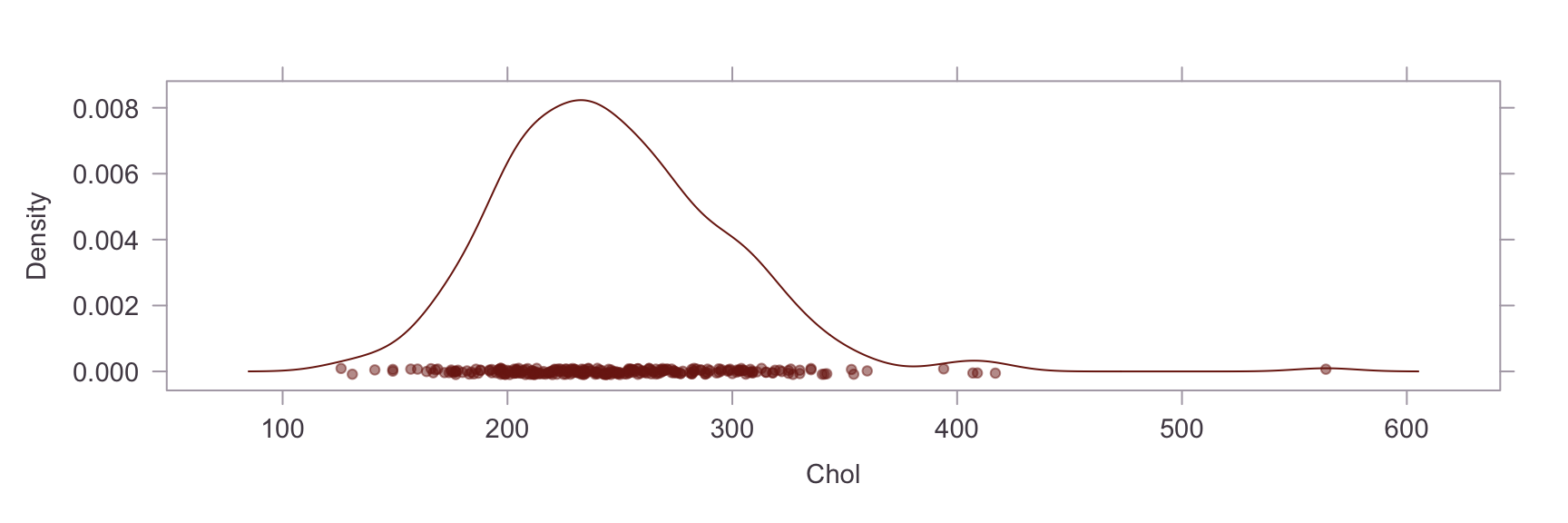
Univariate Distributions #
Next, we show a kernel density plot of each numeric variables.
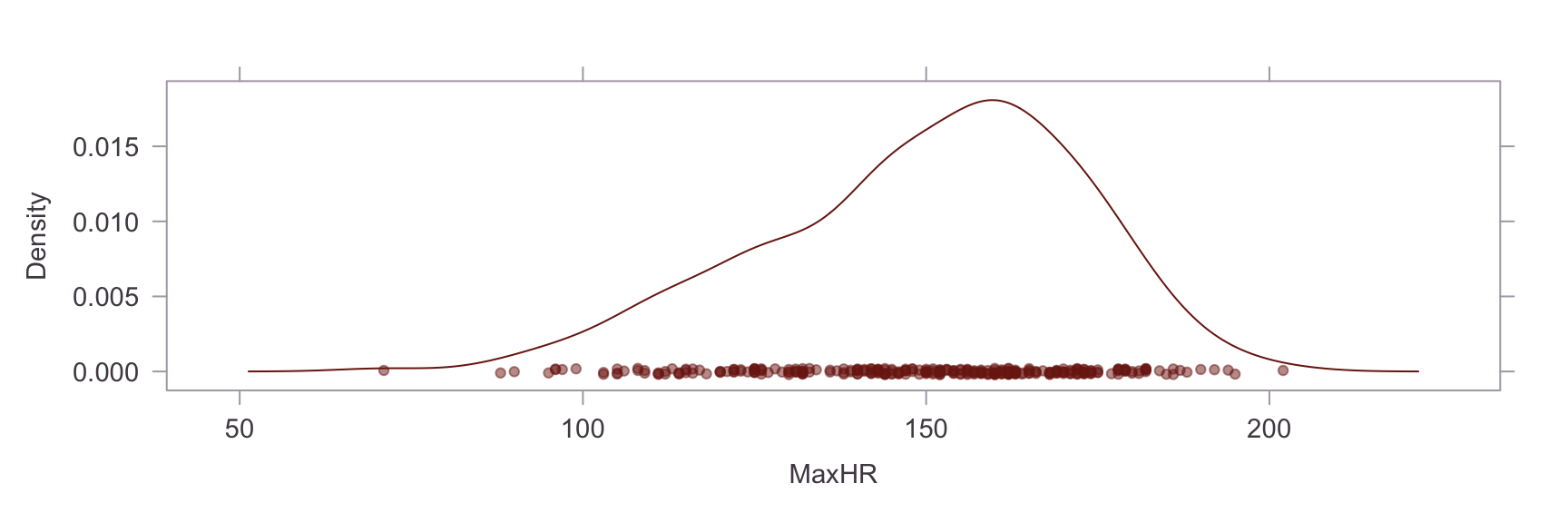
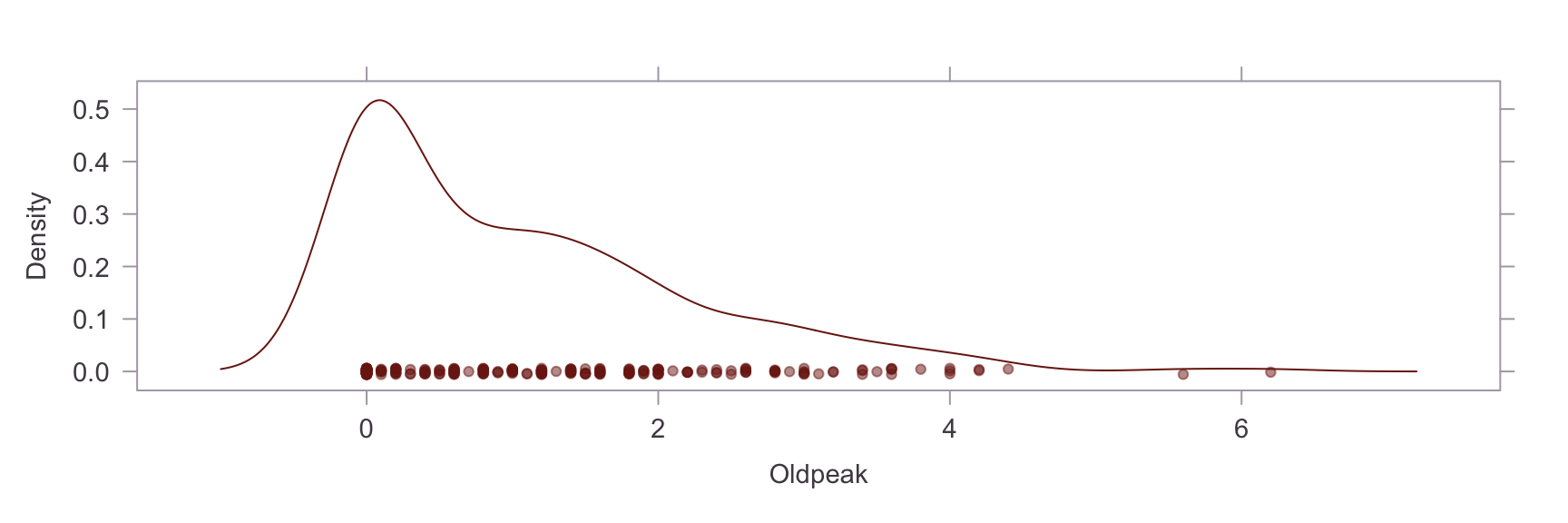
|
|
|
|
A visual inpection of the above plots reveals skew and non-normality in the Oldpeak and Chol variables. This is confirmed by a statistical test for skew, where values of skew >1 are severe. The skew in the Chol variable appears to be caused by an outlier. Briefly researching this matter online, it is apparent that a reading of >200 for cholesterol is already considered extremely high and the problematic reading in our dataset is nearly 600. On the other hand, the Oldpeak variable is systemically skewed. Power transformations are unsuitable for this variable because of the prevalence of zero values, so this will be left as is.
Data Cleansing - Second Pass #
We will perform the following actions:
- Set the outlying Chol value to missing (NA),
- Impute missing values for Chol, Ca and Thal, and
- Scale all the variables between [0,1] - this is to support the distance based clustering techniques that we will use later.
|
|
|
|
|
|
|
|
Bivariate Distributions #
We would now like to look for colinearity or correlation among the predictors. A simple bivariate correlation analysis is conducted.
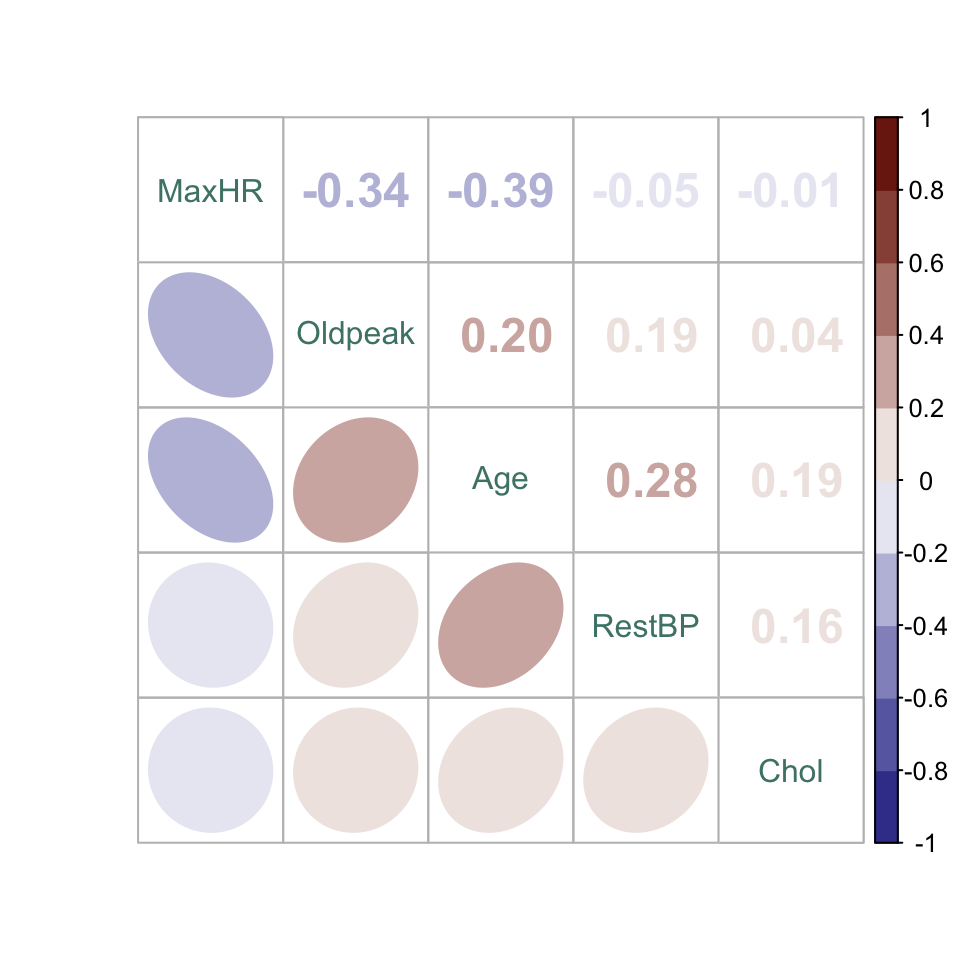
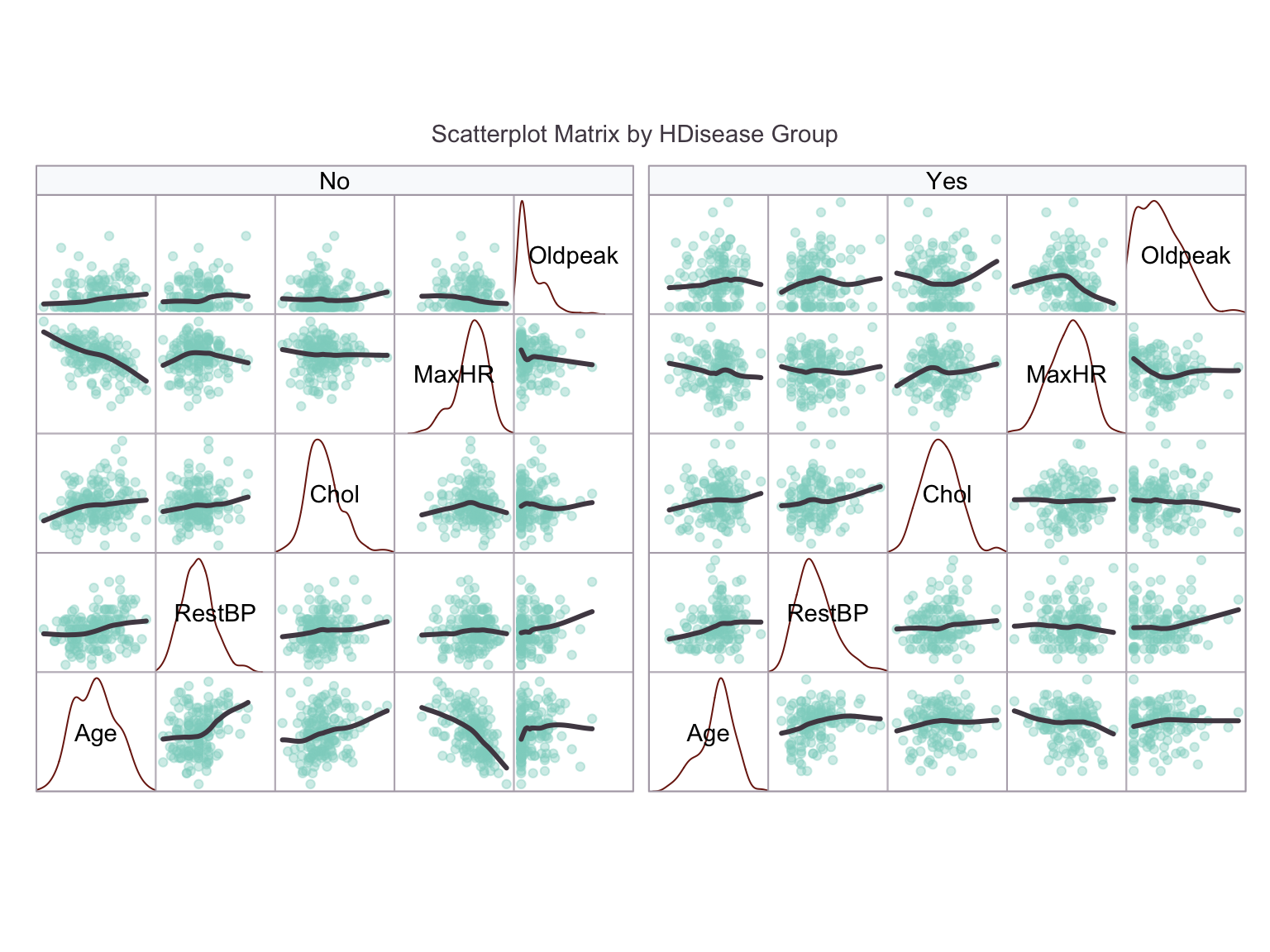
Careful inspection of the splom shows a clear elevation of Oldpeak in the HDisease = Yes group. There is a potentially interesting interaction between Age and MaxHR, which is the pair with the strongest correlation: Specifically, MaxHR is more correlated with Age in the HDisease = No group, whereas MaxHR is slightly lower whatever the Age in the HDisease = Yes group. The HDisease = Yes group are formed from a narrower Age band, indicating that a particular age range could carry higher risk. The remaining continuous variables may be less informative.
Identifying Candidate Predictors #
We now generate a boxplot for each of the five continuous variables, conditioned on each of the factor variables. At this point, we include the HDisease variable to evaluate candidate predictors. This knowledge would be useful prior to developing a classification model of some kind.
The figures that follow need to be assessed row by row.
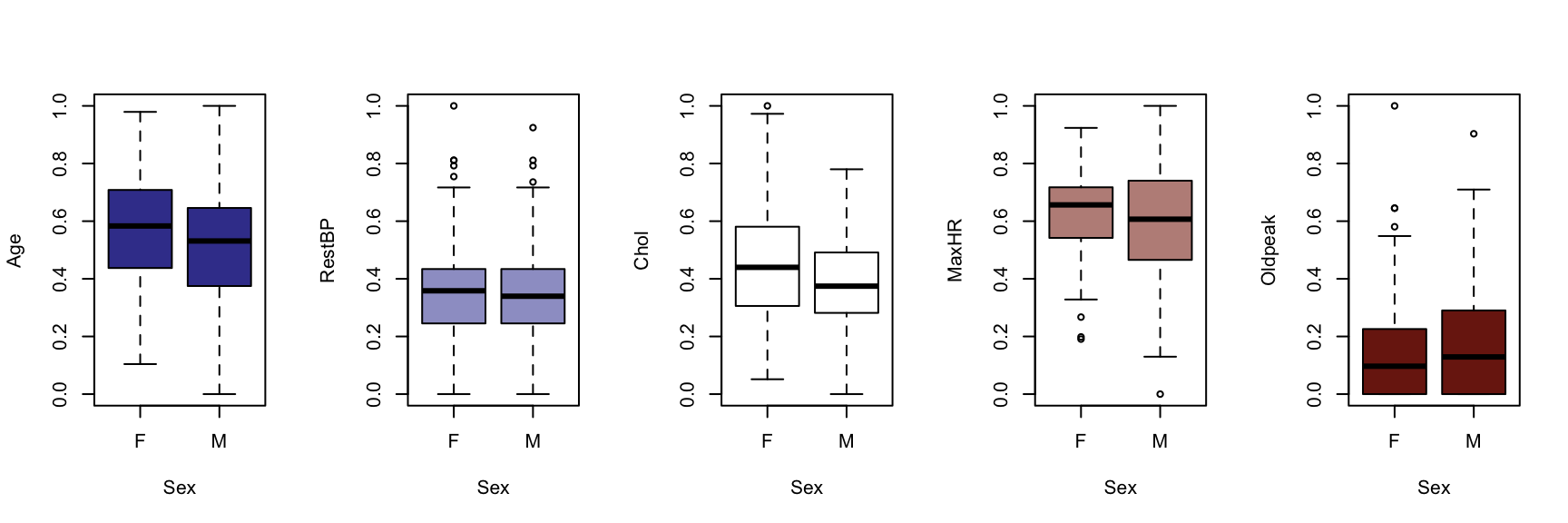
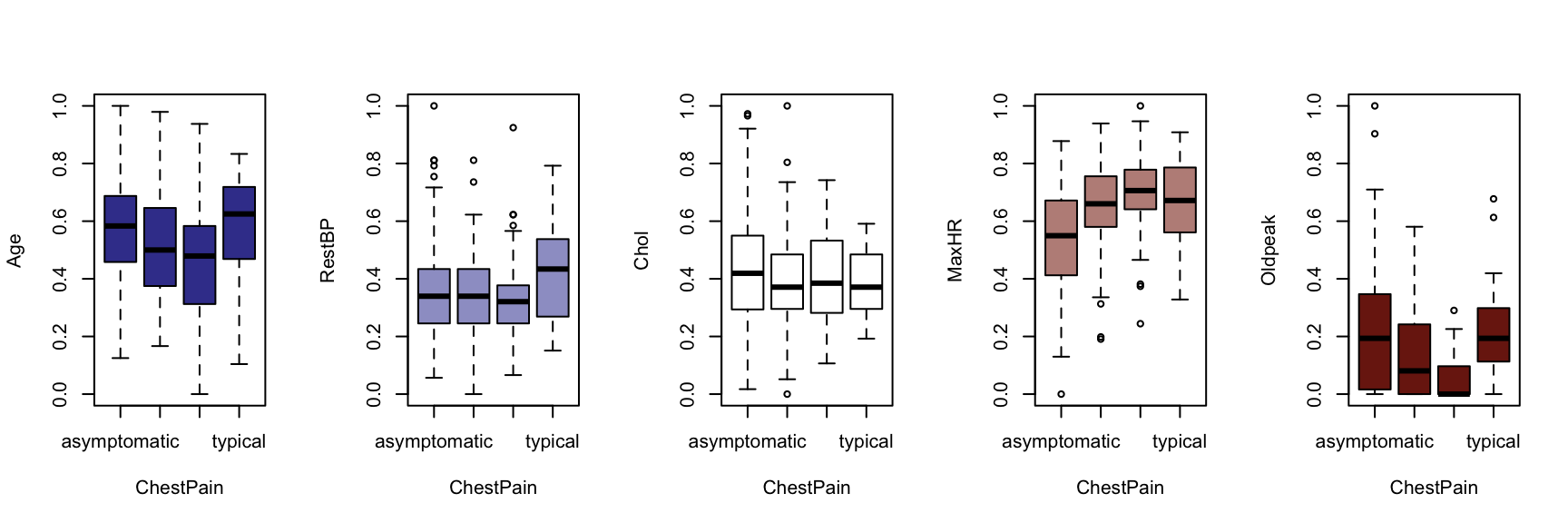
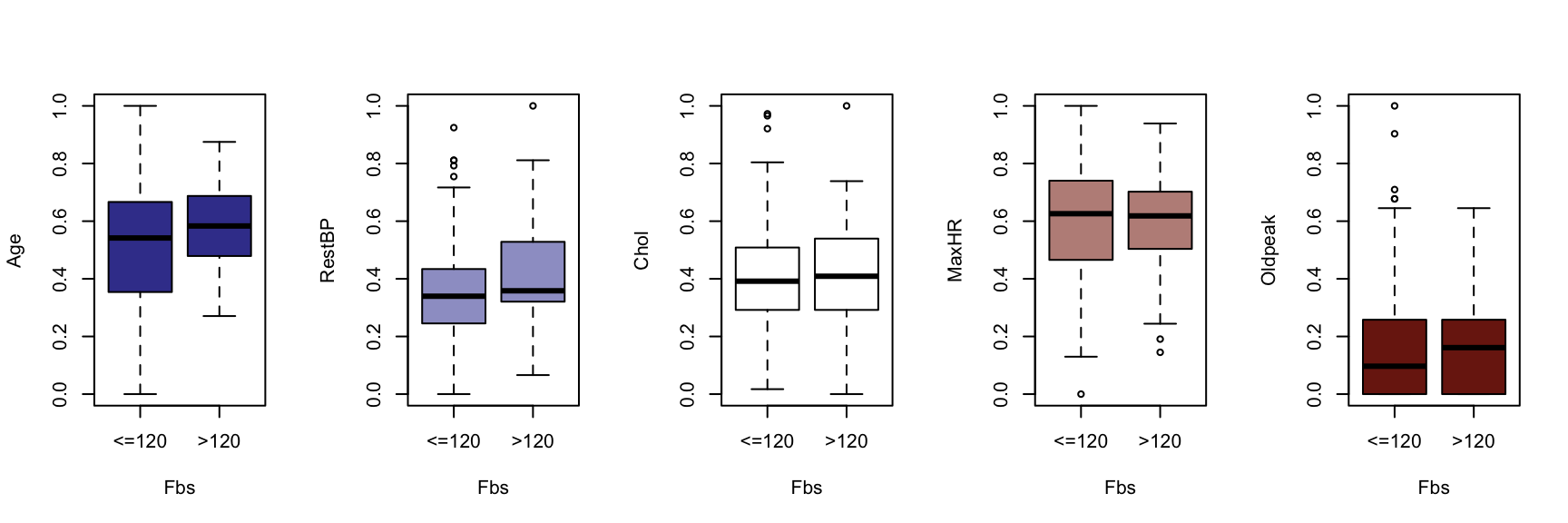
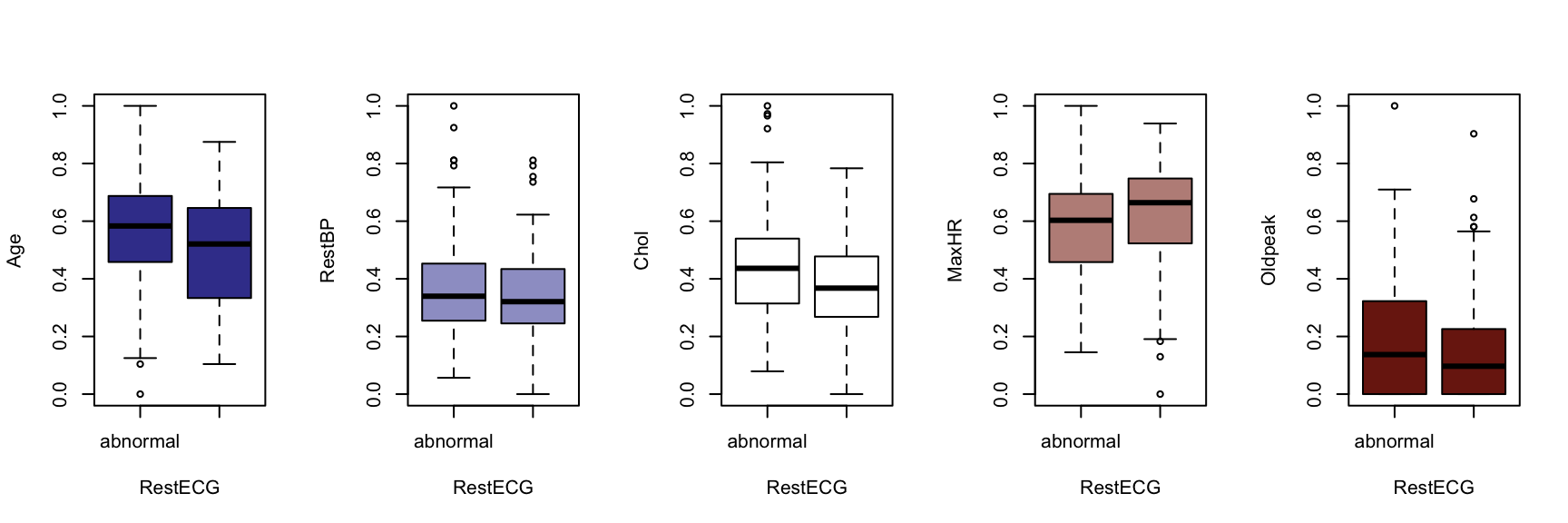
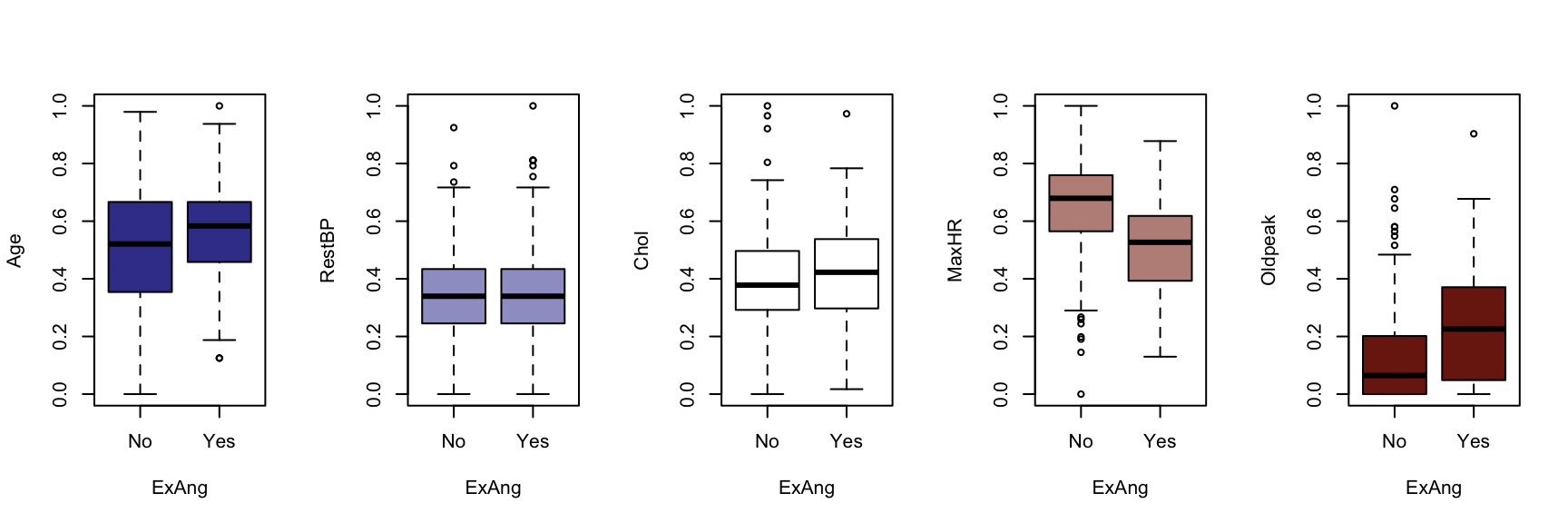
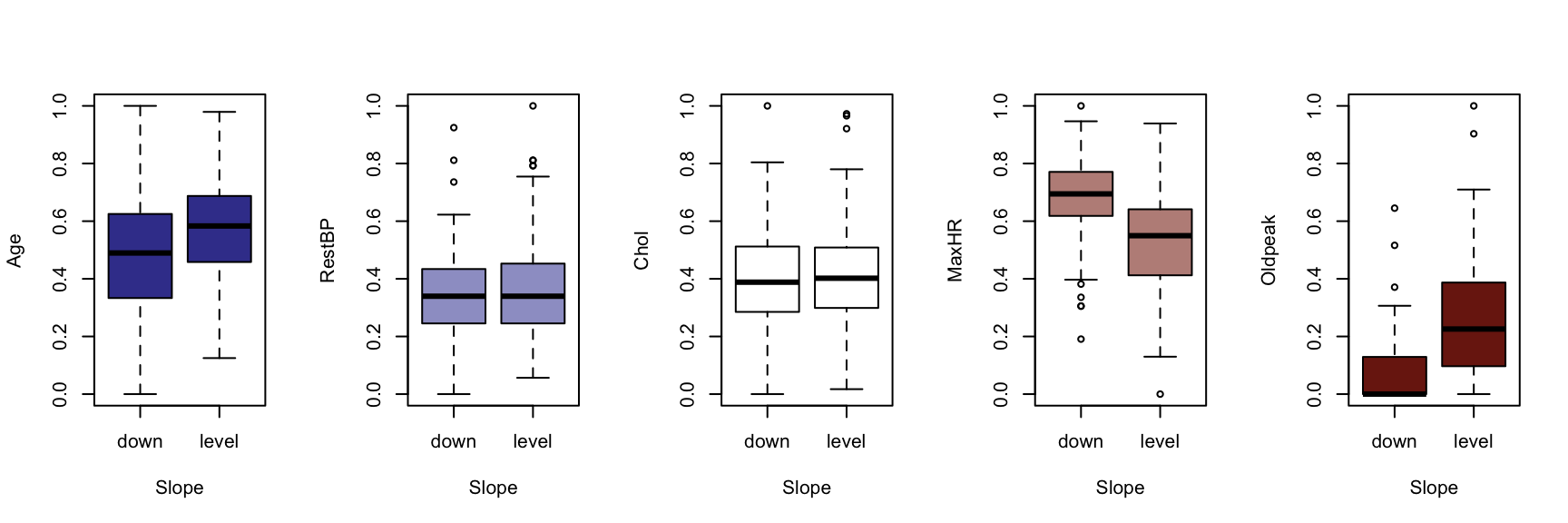
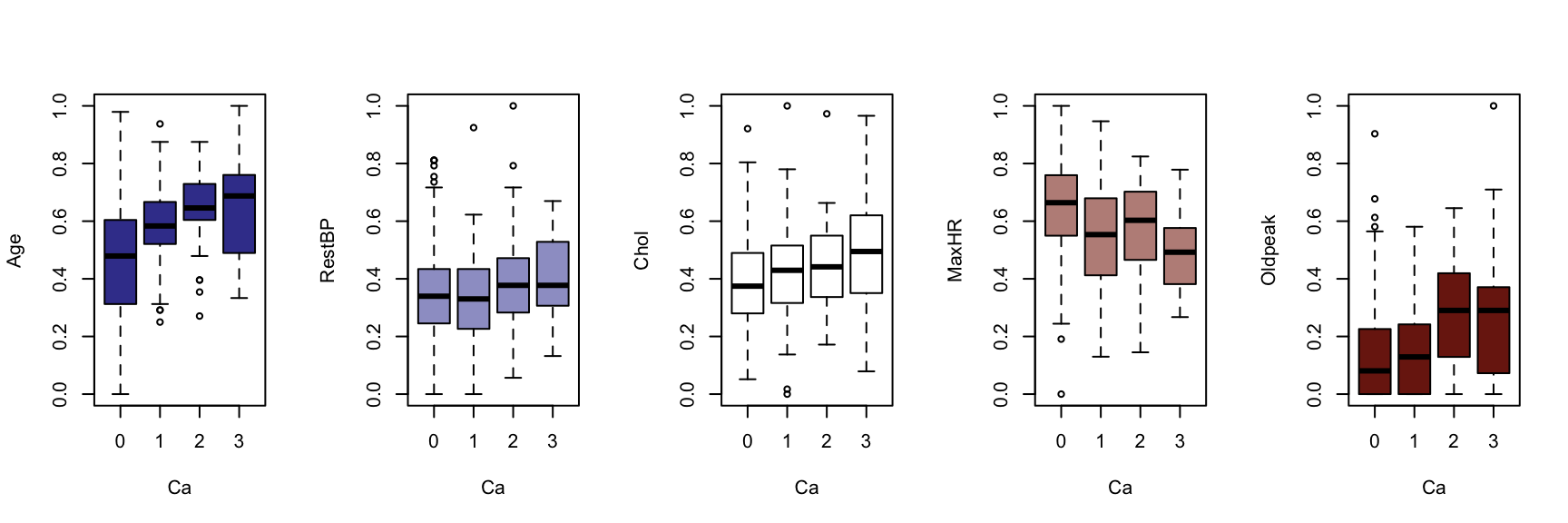
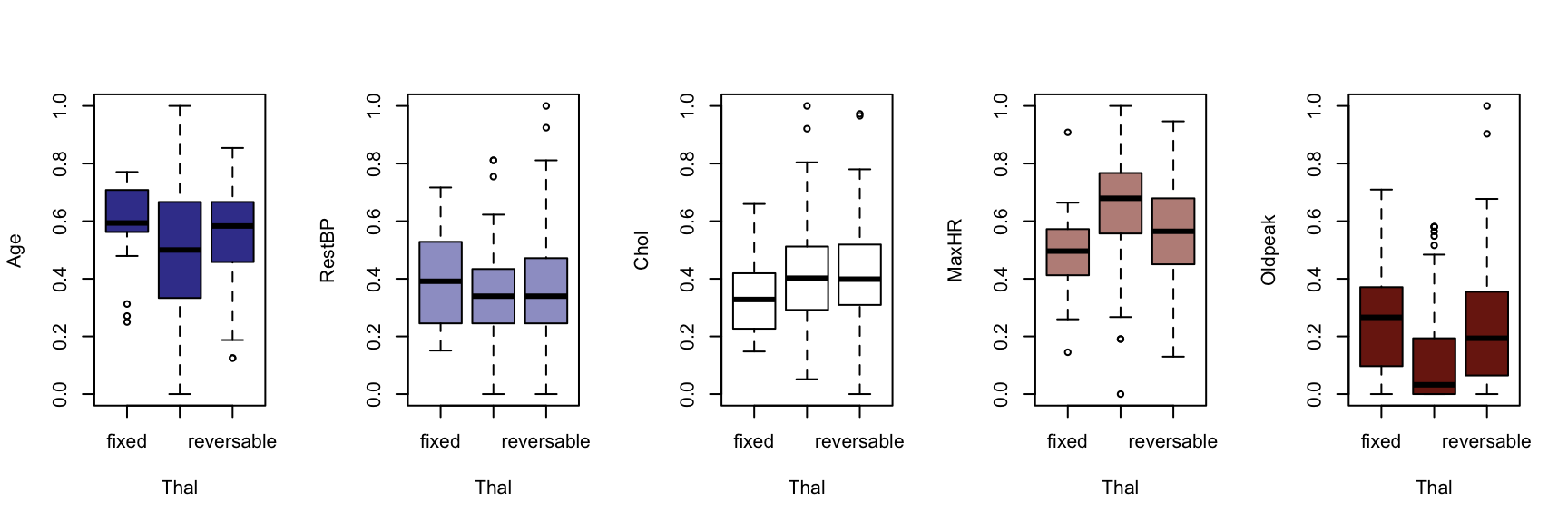
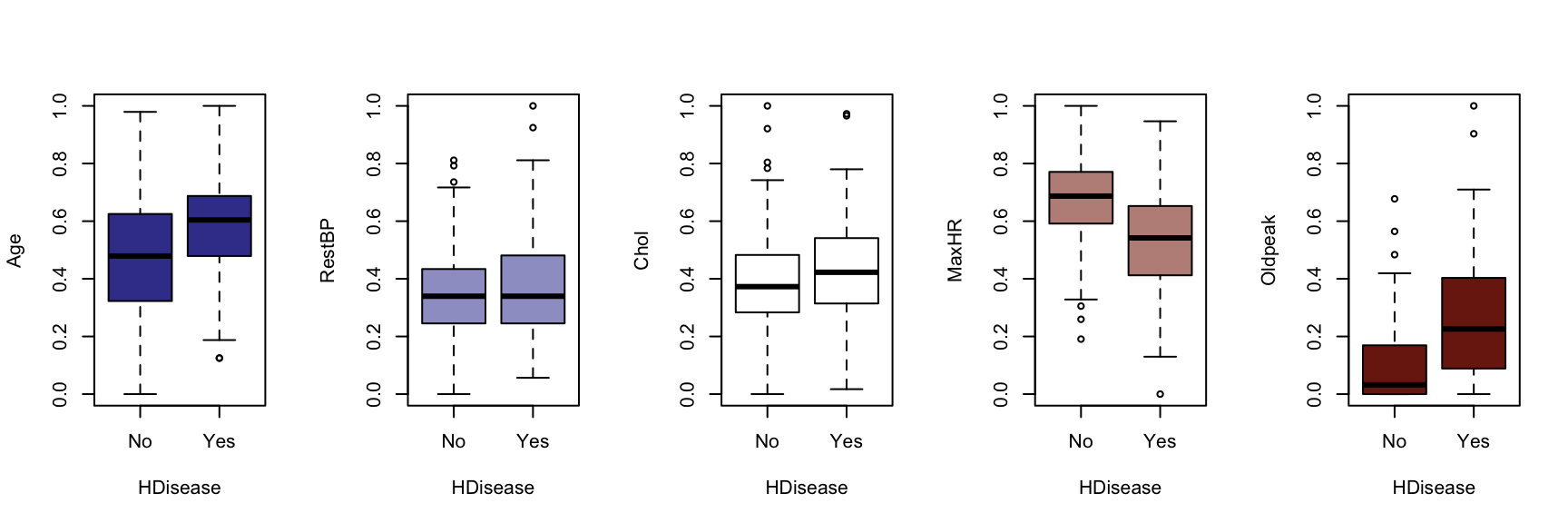
A visual instpection of the boxplots indicates that there may be some interaction between Chestpain and the three informative variables identified previously (Age, MaxHR and Oldpeak). This is also true of ExAng (exercise induced angina), Slope, Ca and Thal. We will not perform any statistical tests at this stage. Fishing for p-values with so many tests requires careful attention to the false discovery rate, and assumptions checking and diagnostics for an unwieldy number of variable combinations. It is sufficient to develop an intuition about the data and interactions.
Multivariate Counts #
Distributions among categorical variables can be assessed according to counts and proportions. The following Fourfold and Mosaic visualisations implicitly perform significance tests by means of shading residuals. Fourfold plots are suited to visualising pairs of binary variables, while mosaics can handle factors with more levels.
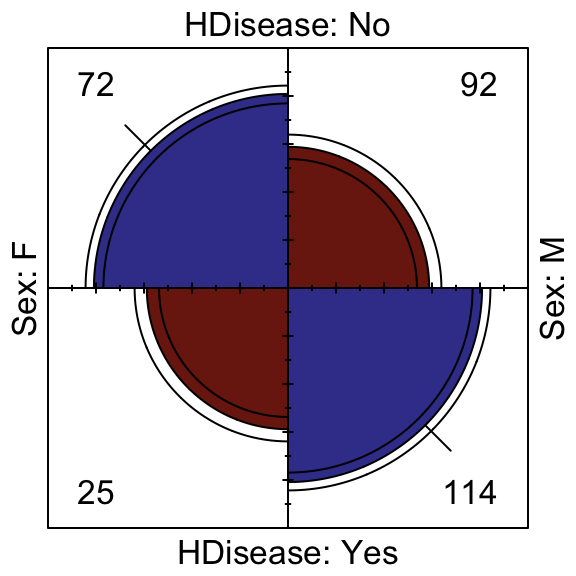
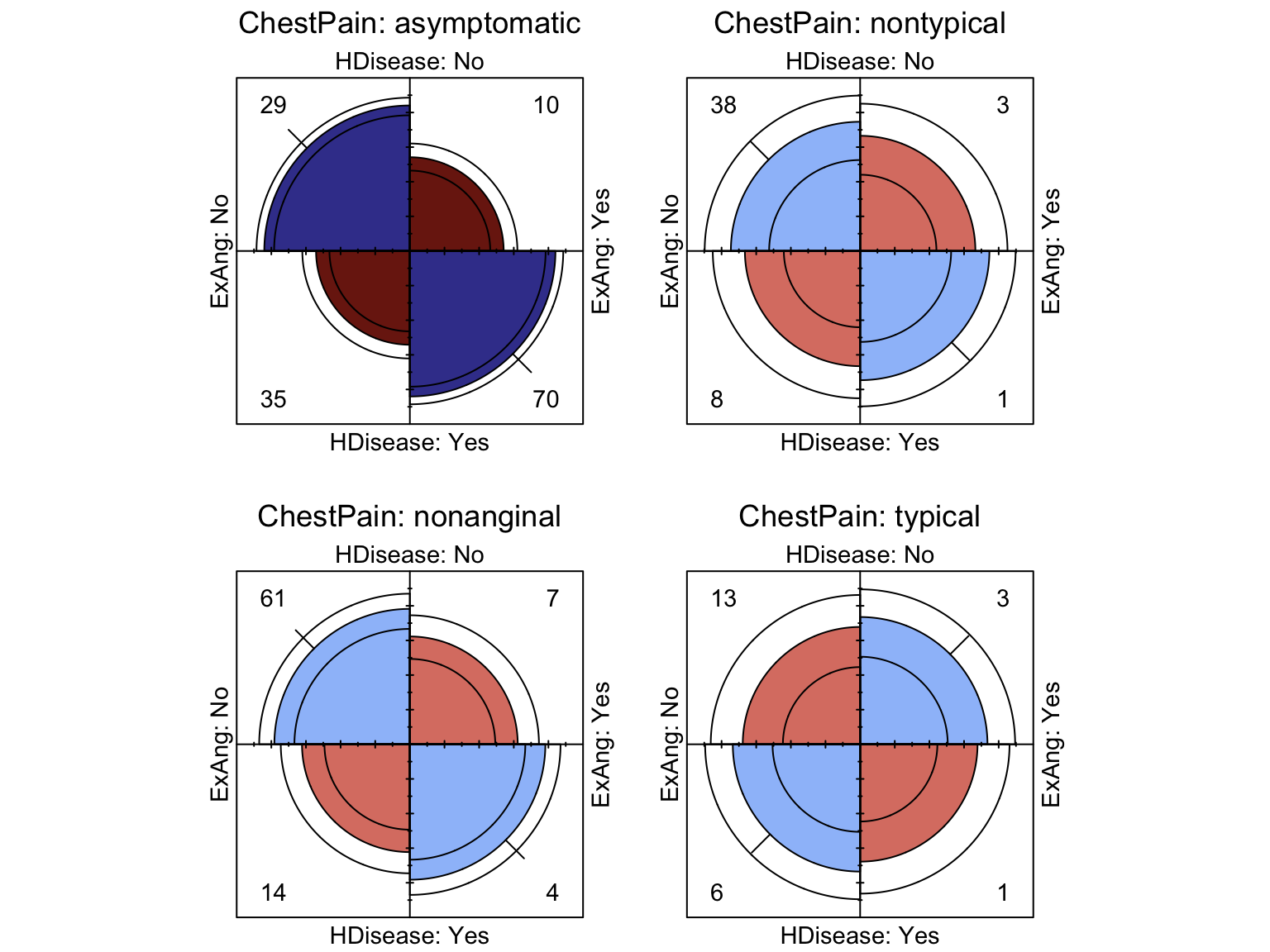
We can see that the presence of atherosclerotic heart disease is significantly associated with males, while a third order interaction exists such that those who are generally free from chest pain but suffer with exercise induced angina have a significant risk of atherosclerotic heart disease.
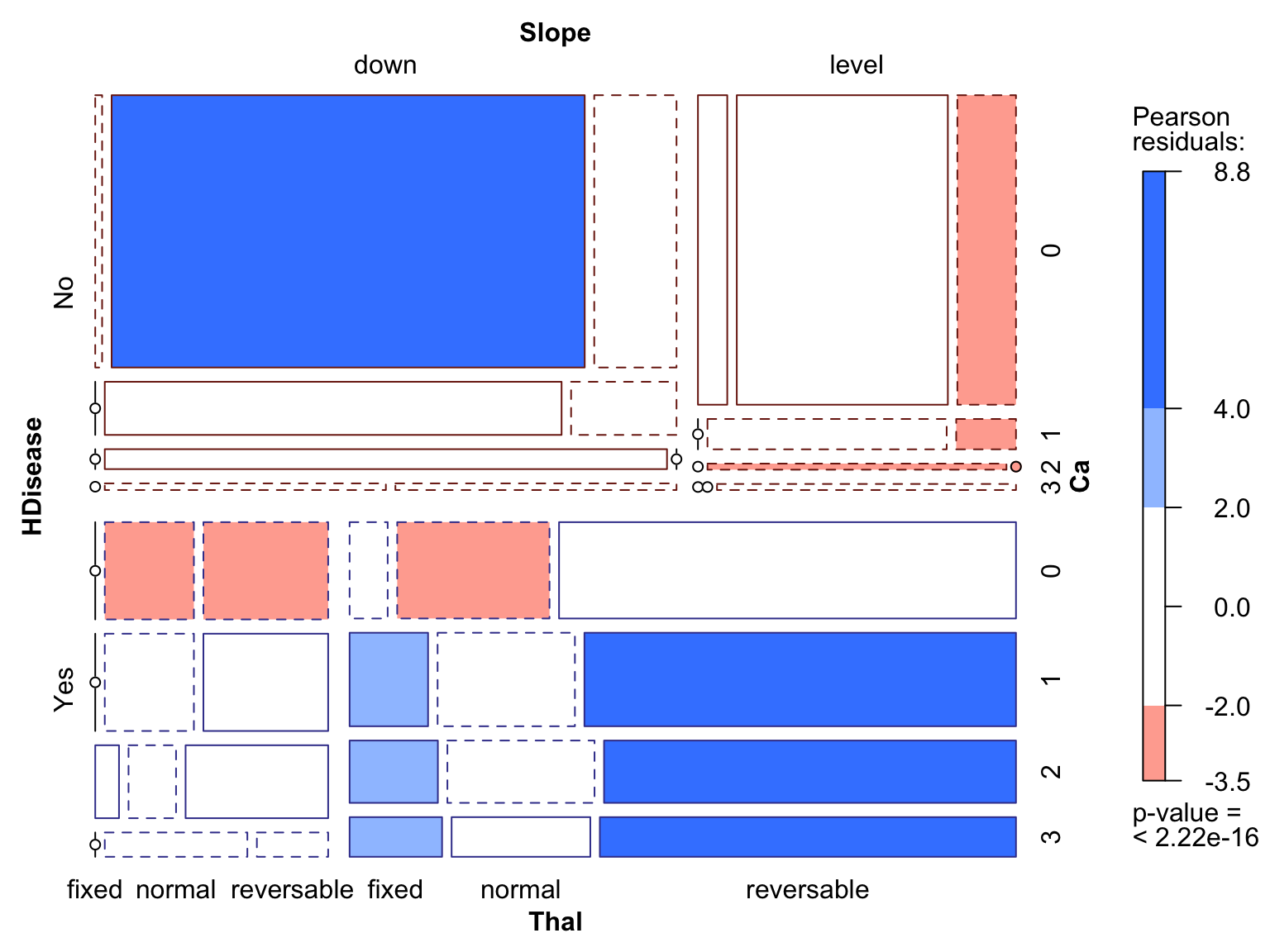
The mosaic plot shows a four way analysis, which requires some explanation to those unfamiliar with this technique. Mosaics plots may look daunting at first, but quickly become intuitive with a little practice. They visualise a recursive partition. In this case, starting on the right with HDisease, the plot canvas is split horizontally into two tiles for “Yes” and “No”. Going clockwise, the tiles are split vertically for Slope “down” and “level”. Next, the tiles are split horizontally again for all the levels of Ca, into the existing two levels of HDisease. Finally, the collection of tiles are split veritcally once more for each level of Thal into the Slope levels. At each split, the tile areas are set to be proportional to the count at each intersection of variables. Independent variables would show up as evenly spaced and evenly sized tiles, where each tile would be proportional is size/count to the marginal totals. Discontinuities in the slice lines show up when an intersection between variables contains significantly more or fewer counts than expected under the independence assumption. When this occurs, the tiles are shaded in a two level gradient: blue/red for positive/negative association compared to the independence assumption, which aids the observer in understanding positive and negative associations. The shading values are based on the residuals when compare to a non-significant \(\chi^2\) test.
We can see that downward slope is most associated with the HDisease = No group and level slope for HDisease = Yes. Similarly, one or more arteries visible under fluoroscopy (Ca) are most strongly associated with HDisease = Yes. A third order interaction indicates that a combination of level Slope and reversible Thal is very strongly associated with HDisease = Yes, with fixed Thal also being strongly indicative.
Unuspervised Learning Methods #
We continue with a more advanced exploration of this data set.
PCA #
The first method we will exlore is principle components analysis (PCA) on the scaled continuous variables. PCA identifies orthogonal projections of multivariate data that capture most of the variation in the first components.
|
|
|
|

We can see from the output summary that Age and Oldpeak are loaded onto PC1 in the opposite direction to MaxHR, indicating a negative correlation. The other PCs can generally be interpreted according to further relationships among these variables, some of which we have already seen in the bivariate correlation analysis. It seems from the cumulative variance measure and the scree plot that the projection of these five numeric features onto less interpretable principal components does not offer any obvious gains; it still takes four components to capture most of the variance, nearly the same number as the raw variables. Nevertheless, we can make a biplot in an attempt to better understand the multivariate relationships.
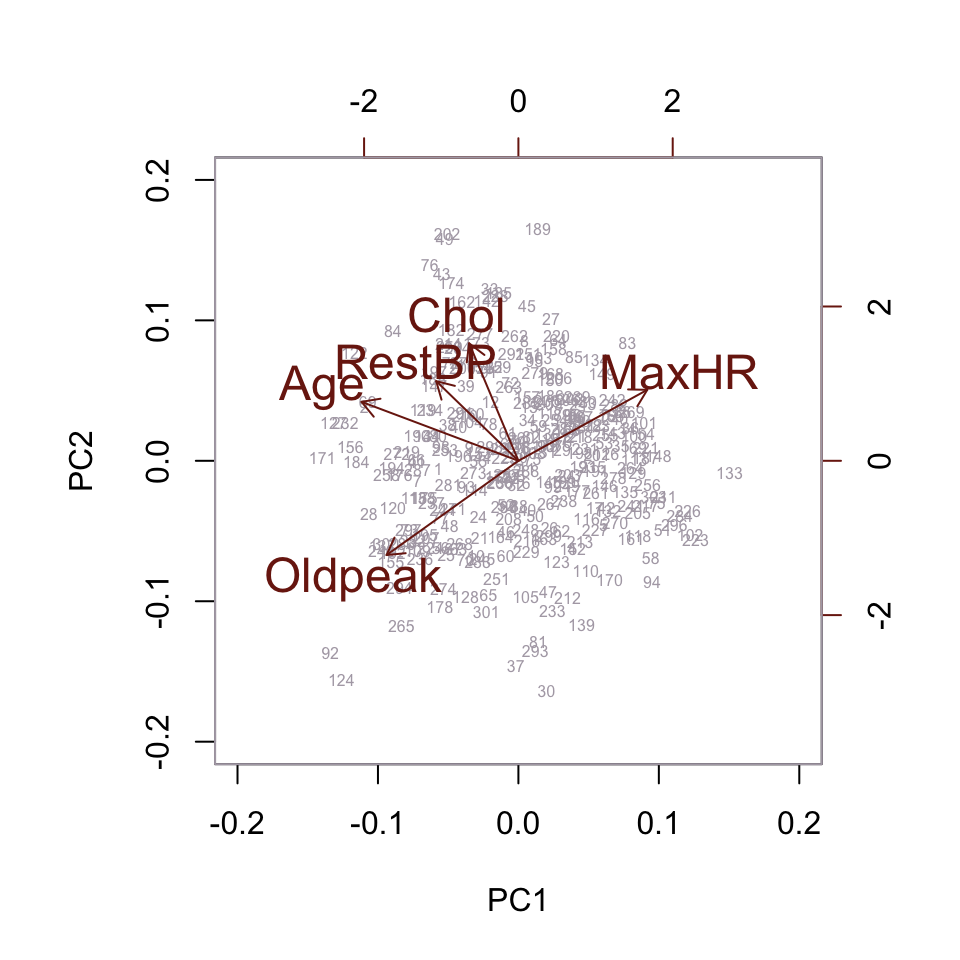
The biplot doesn’t reveal any useful new information, so we proceed to the next technique.
Multiple Correspondence Analysis #
Multiple correspondence analysis is a dimension reduction and clustering analysis for categorical counts. Variables with strong count associations tend toward the same direction in a biplot, and we would expect some of the relationships revealed in the mosaic plot above to be evident here as well.
As with PCA, the relationships among several or many categorical variables can be mapped in two dimensions, giving fairly intiuitive results. A less well-known benefit is that categorical variables are implicitly re-coded into non-abritrary numeric values. This makes them available to use in any methods that only accept real-valued inputs, such as distance-based methods like k-means or hierarchical clustering.
|
|
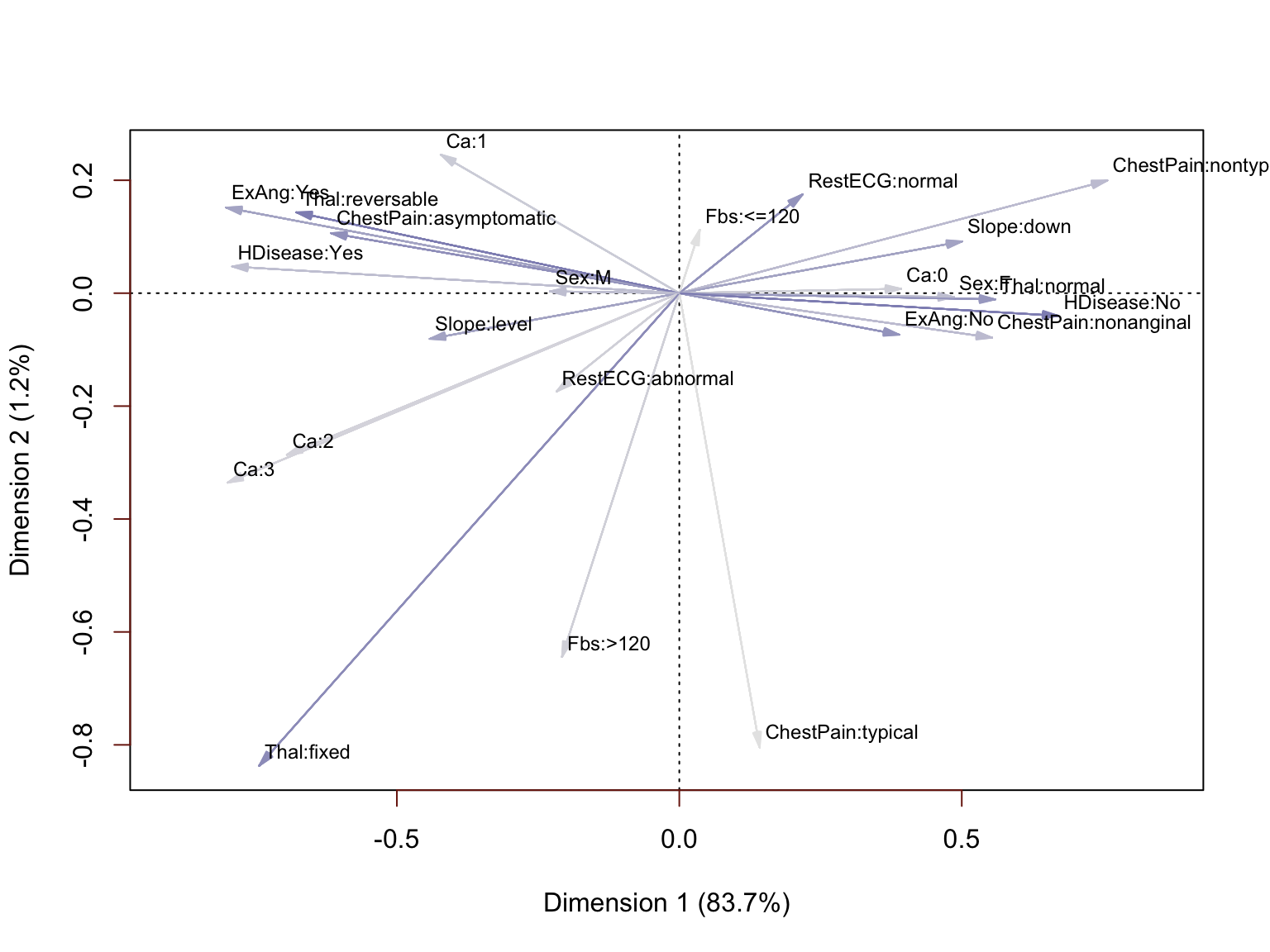
The results of this analysis are indeed rather interesting and confirm the findings of the initial explaratory analysis. The plot can be interpreted by identifying attributes that have moved in the same direction from the origin (0, 0), with particular interest in those that have clustered close together. We can see the specific values of ChestPain, Slope, Ca, ExAng and Sex that are associated with the presence of absence of heart diseease. We also have confirmation that Fbs is much less correlated with HDisease and RestECG only moderately correlated. If we were going on to do predictive modeling, this analysis would provide a stong case for excluding them. In fact, we will re-run this analysis excluding those variables to demonstrate the impact.
|
|
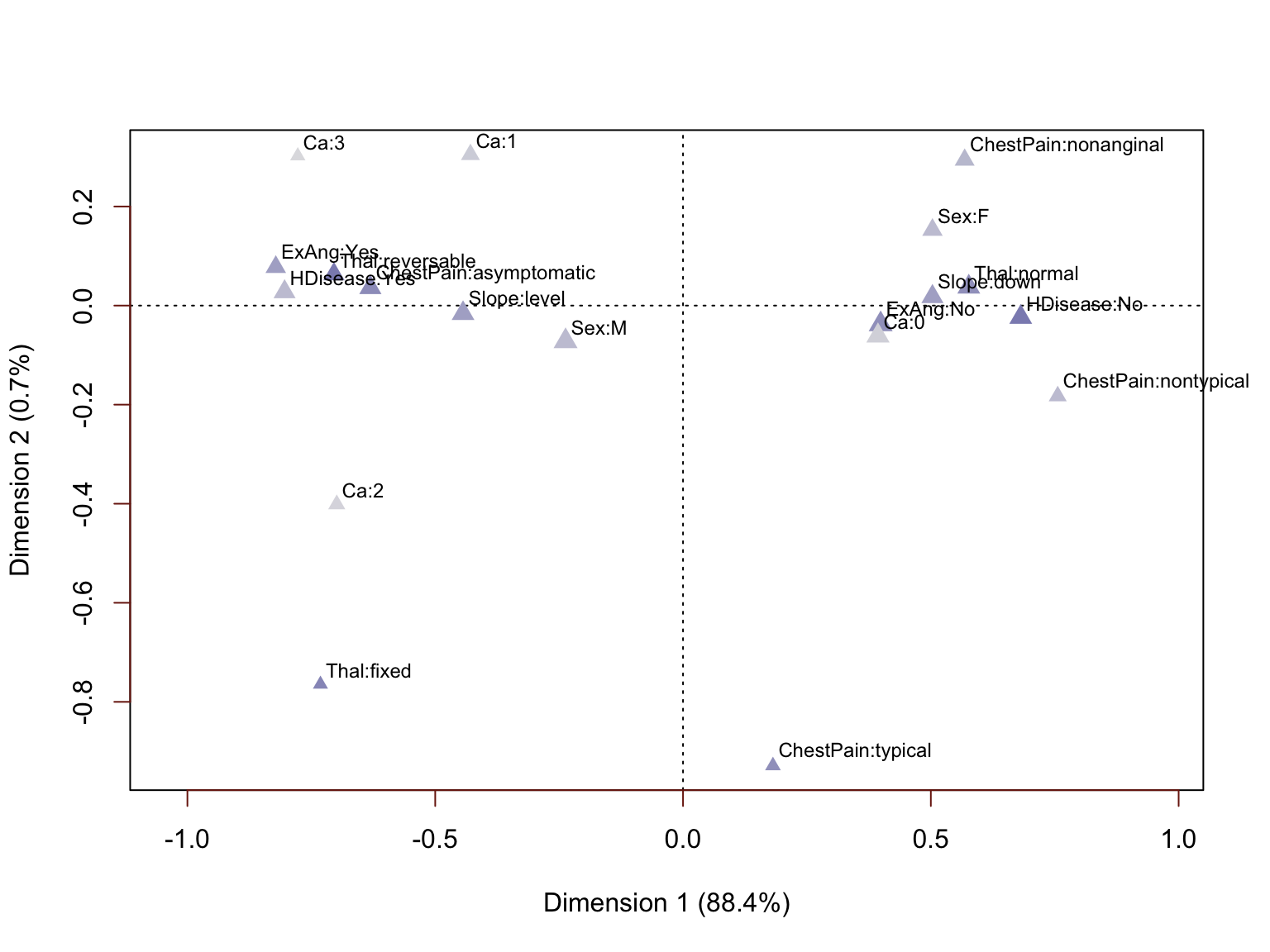
We are not displaying the arrows this time because the labels themselves are rather crowded and hard enough to read without the extra visual clutter. We can see that the clusters are very pronounced and we can once again identify a handful of less informative attributes. For example, Thal=fixed and ChestPain=typical represent small minorities in the way these variables are distributed.
We can augment this analysis by discretizing the numeric variables and including them as well. This will be done by binning into low and high levels.
|
|
|
|
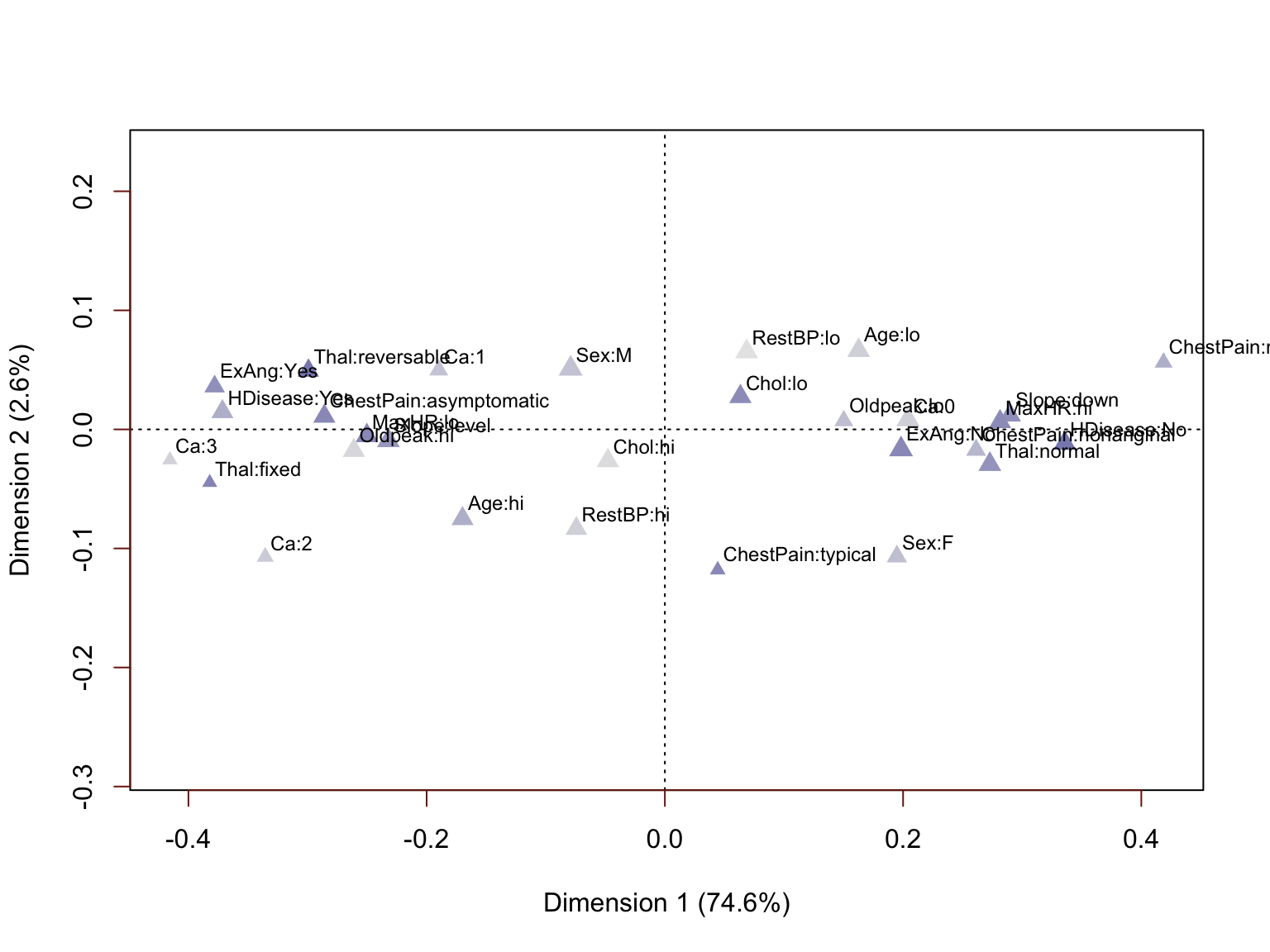
This plot takes some time to interpret, but a careful look further confirms results of our previous analyses. The lowest MaxHR values are associated with heart disease and the highest values with absence of disease. Increasing Age is generally associated with presence of heart disease. Increasing Chol is associated, but only very moderately (the Chol attribute levels are not separated widely on the horizontal dimension). The same is true for RestBP. Let us re-run this once more, excluding these two less correlated variables. We also exclude the HDisease label as we do not want it to influence the resulting numerical values.
|
|
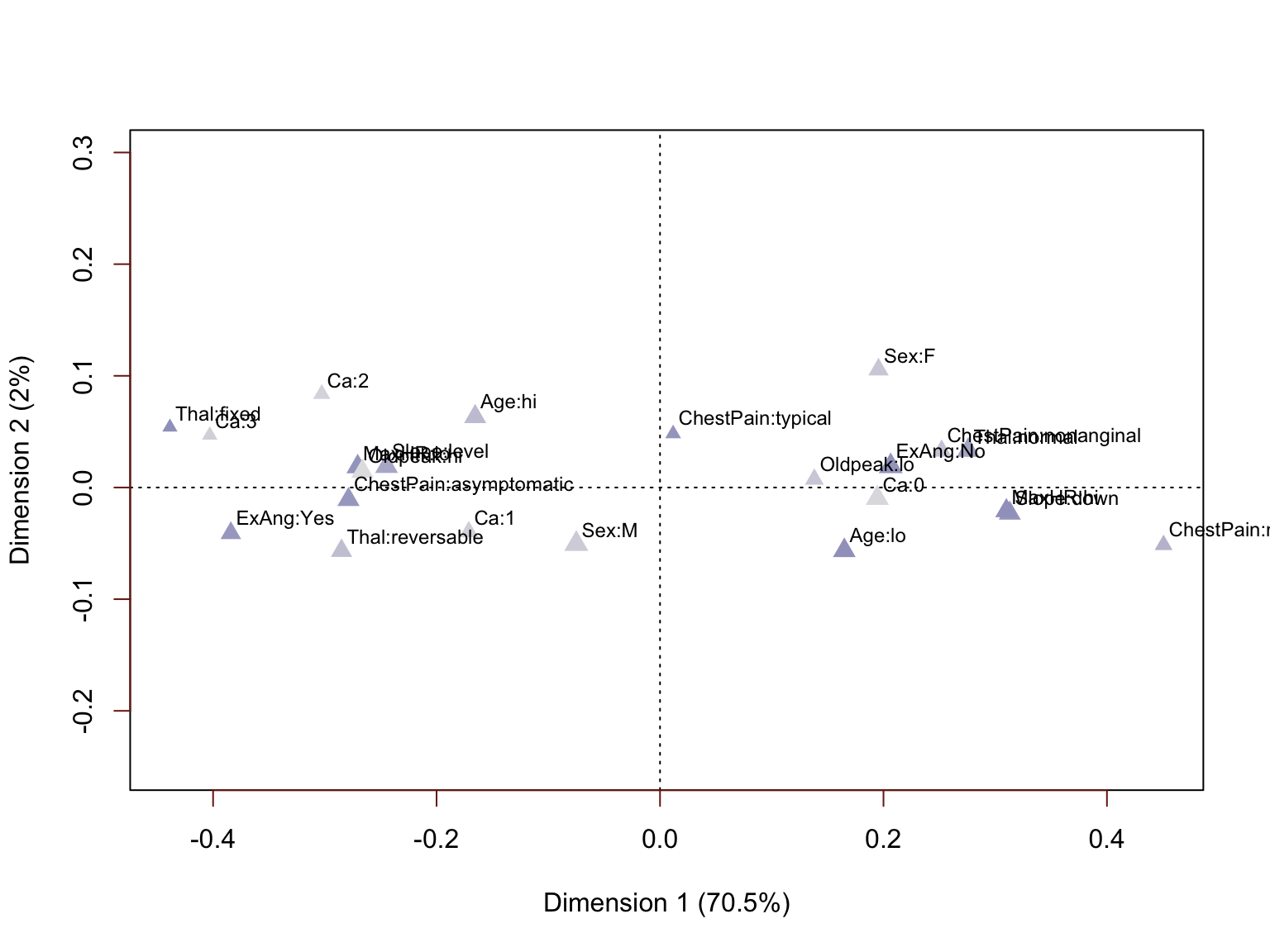
|
|
This multiple correspondence analysis provides two very well differentiated clusters of attributes. This result was generated in the absence of the HDisease variable, yet we have plenty of reason to believe that these engineered variables we could are strongly predictive. Nearly all the inertia (variance) is captured on the first dimension, we can use the one-dimensional coordinate values from this dimension as numerical proxies for the categorical attributes in the analyses to follow.
|
|
Distance-based Clustering #
Now that we have selected our variables of interest and converted categorical values to non-arbitrary real-values, we can continue with distance based clustering. The following visualisation is a map of all the Euclidean distances between the points.
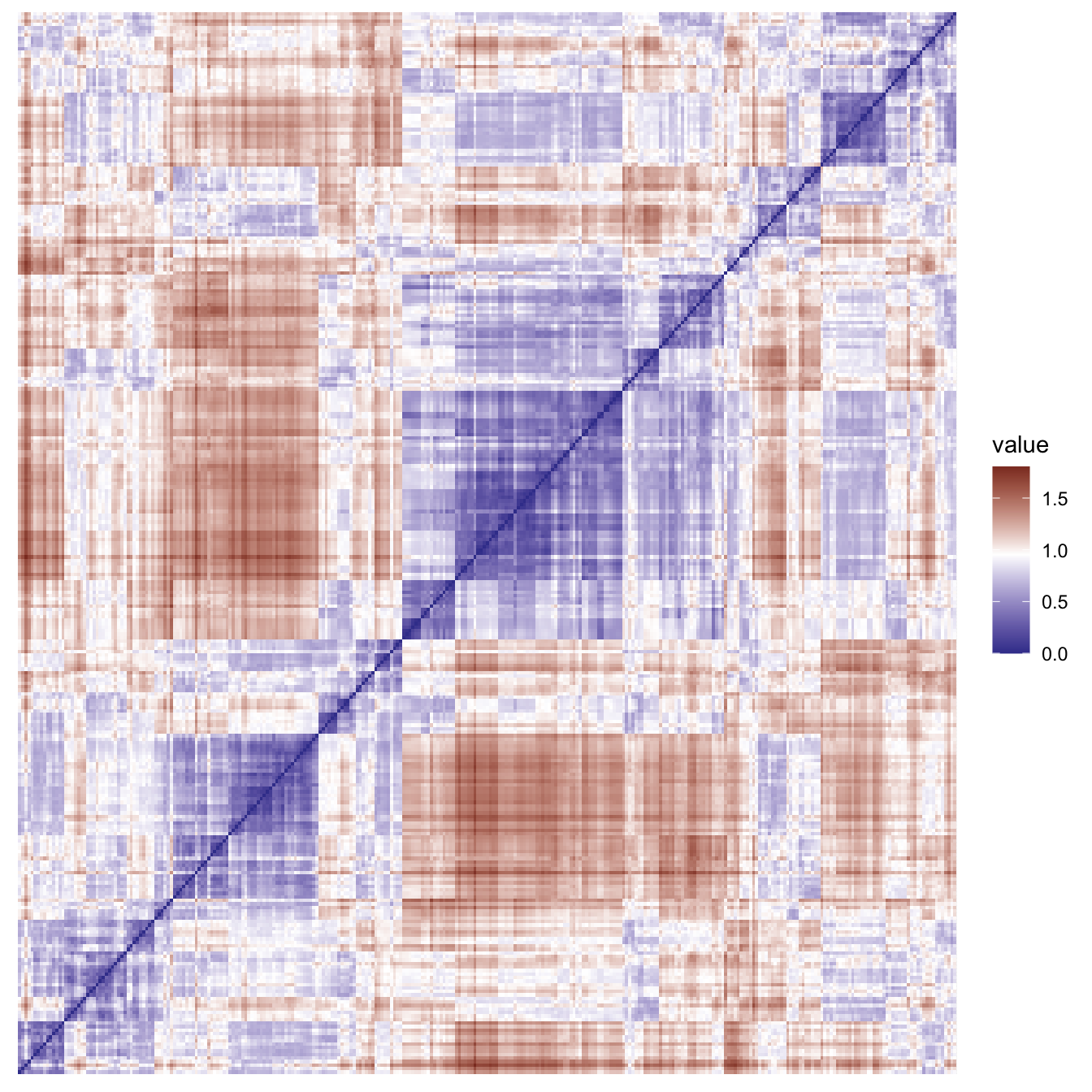
This visualisation provides a useful confirmation of the clustering tendency in this data. We can also compute the Hopkins statistic H, which tests the null hypothesis that the data has come from a uniform distribution and is distributed as \(H \sim \mathit{Beta}(n, n)\) where n is the number of samples used to calculate the statistic. Values of H 0-0.3 indicate regularly-spaced data. Values around 0.5 indicate random data. Values 0.7-1 indicate clustered data.
|
|
|
|
This H value indicates very well clustered data.
K-medoids Clustering #
K-medoids searches for k archetypal or representative instances, called medoids that act as the cluster centres. Each non-medoid instance is assigned to its nearest medoid. The algorithm proceeds by swapping medoid and non-medoid points, accepting a swap that decreases the sum of a dissimilarity function. K-medoids is less sensitive to outliers than the classic K-means method, so is often favoured. Another reason to prefer K-medoids is that the number k can be estimated using the silhouette method. From the knowledge we have already that these variables tend to be associated with presence or absence of heart disease, we could assume two clusters is the correct number, but it’s still worth checking using this visual inspection.
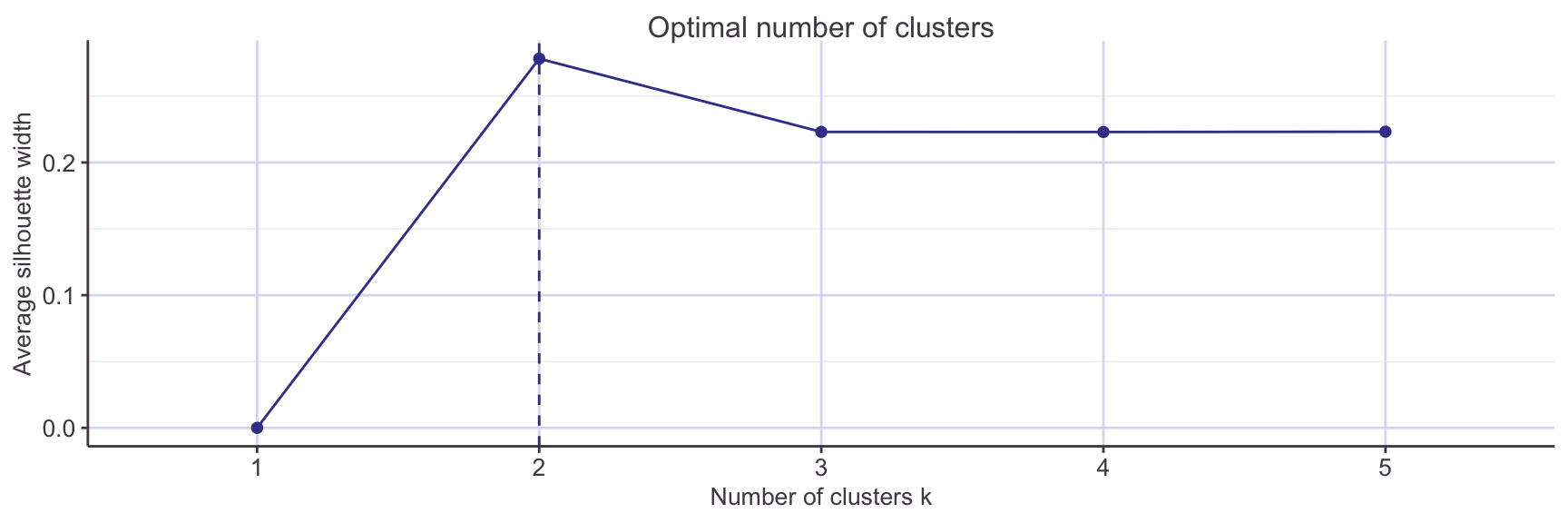
With confidence we can run the clustering with k=2:
|
|
|
|
Recall that HDisease was not included in the real-valued data cpnversion nor the clustering process. Cross-tabulating the instances from the original dataset shows a “confusion matrix-like” result, indicating that the two clusters have captured the association with heart disease among the variables of interest. The cluster labels are arbitrary in this unsupervised learning process. We can set the appropriate label to the cluster id and get a full suite of diagnostics:
|
|
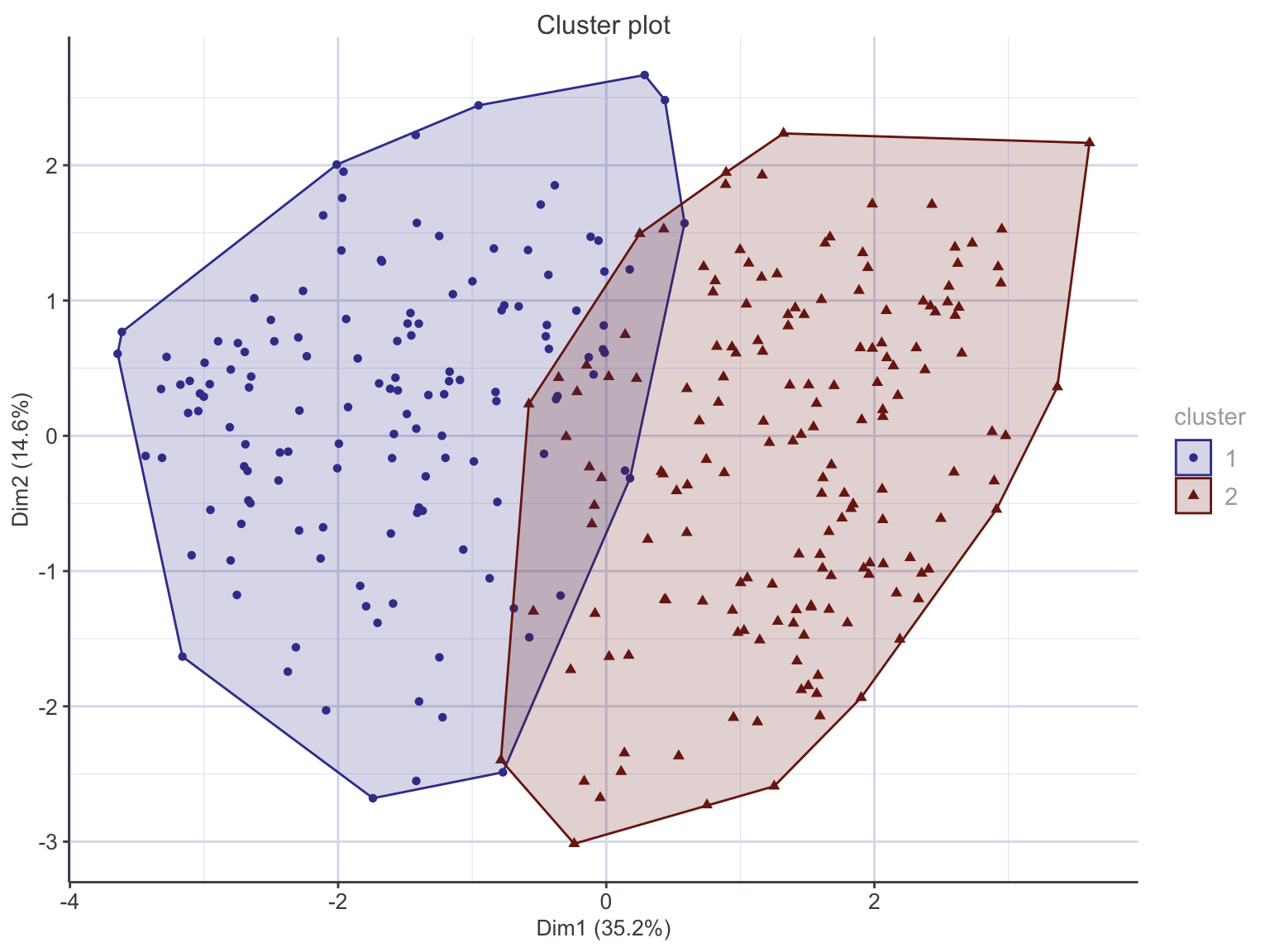
We can see that if we assigned new, unlabelled points to their nearest cluster medoid, we might expect an accuracy of around 0.83
Hierarchical Clustering #
We can do something similar with hierarchical clustering. After some experimentation with different clustering methods, the “Complete” method was chosen as it produced two distinct clusters with similar numbers of members.
|
|
Again, we can speculate on the accuracy we would get on prediction using just the cluster membership. This yields a slightly lower overall accuracy, but an increased specificity, or True Positive Rate. As such, this method might be more suitable when designing a diagnostic tool.
We can plot dendrograms of hierarchical clusters and colour the leaves using any factor variable. This provides a visual inspection of how the factor is distributed among the clusters, starting with the HDisease variable that we might want to classify at some future time. Again, recall that this “target variable” was not used in the clustering algorithm yet we can see that it is well separated into the two clusters. Note, the colours are arbitrary. What is interesting is how they have separated so well into prevalent groupings between the two clusters.
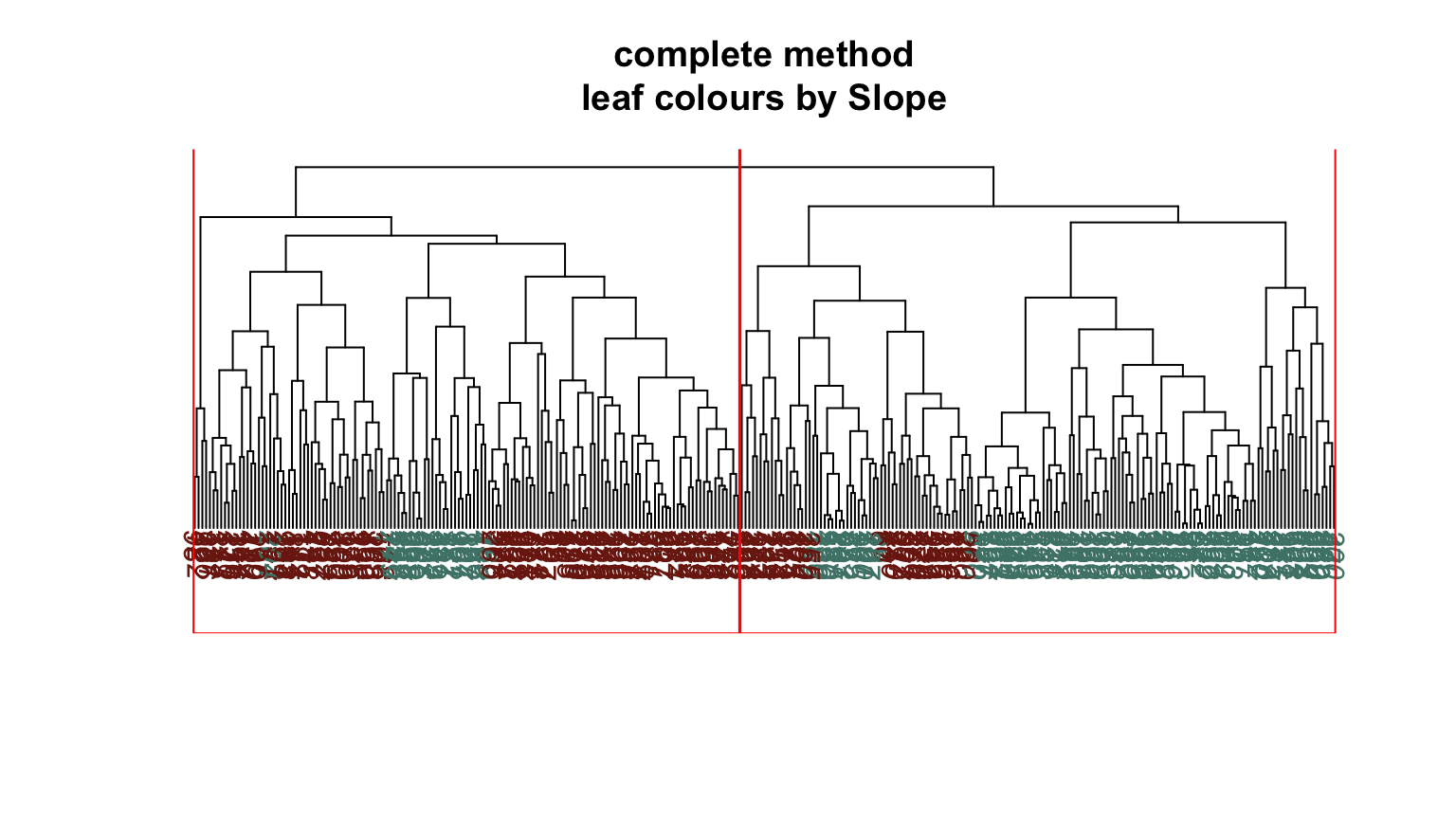
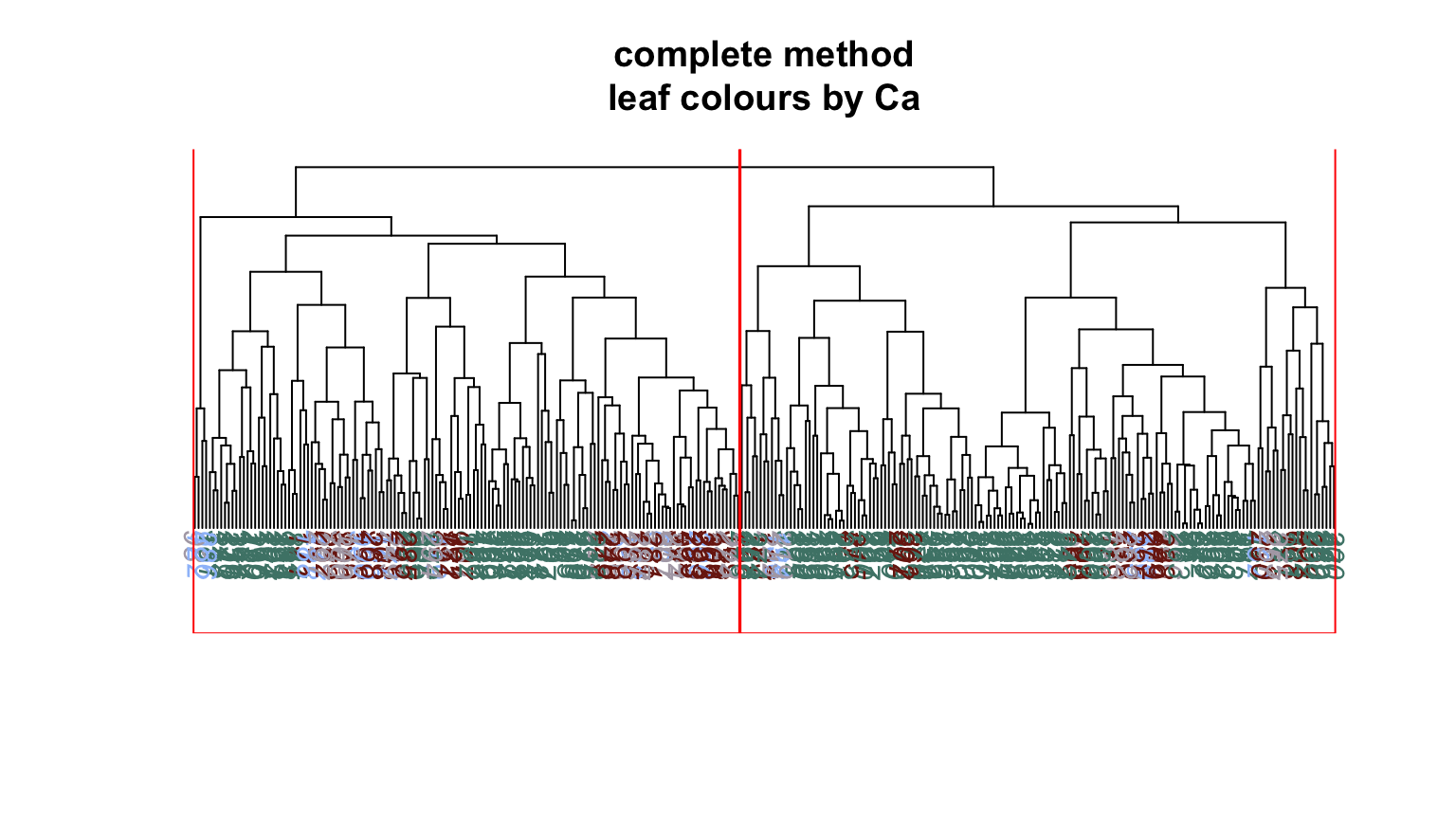
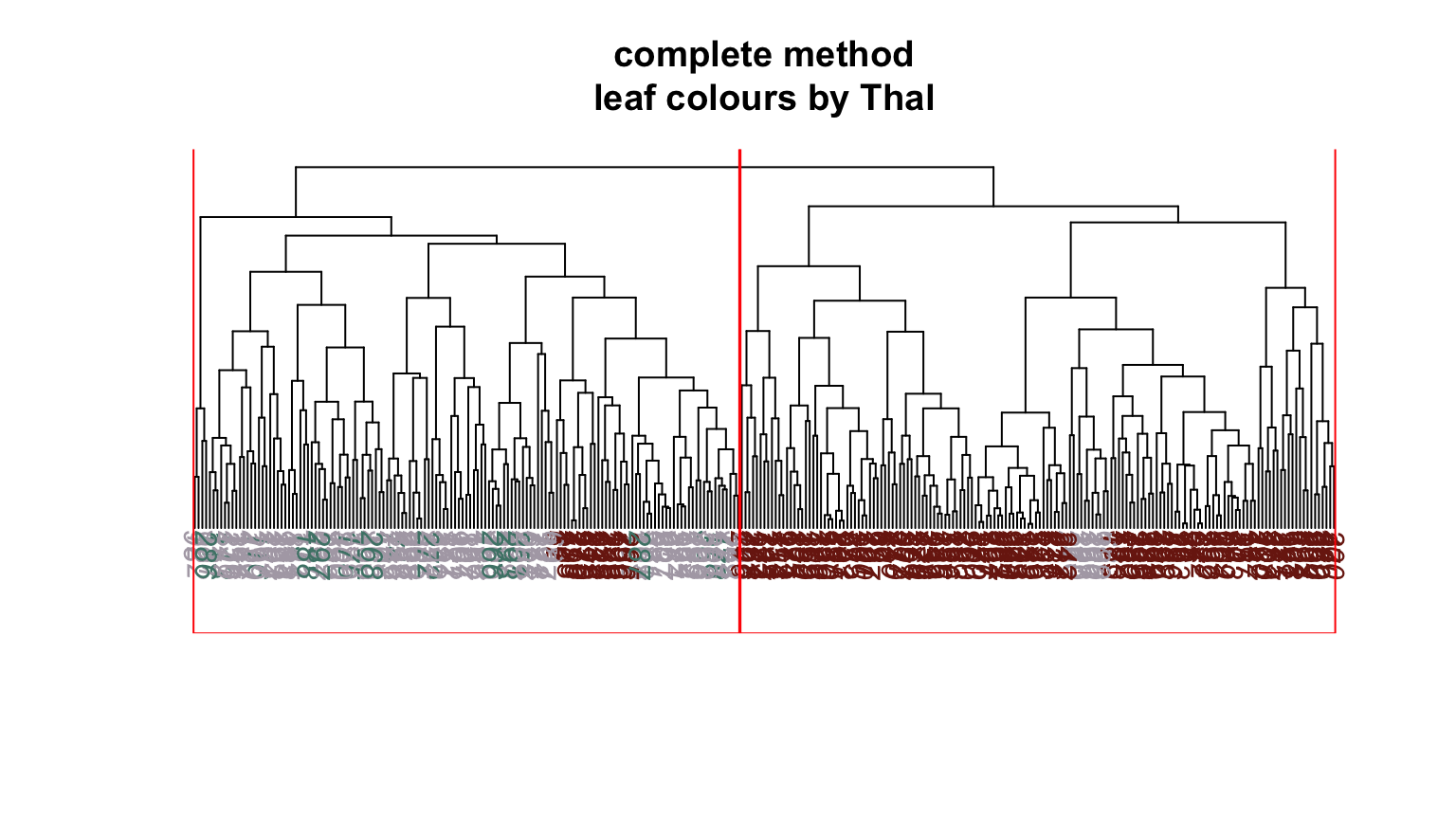
Conclusion #
We have performed a thorough exploratory analysis of the UCI Heart Data and used unsupervised machine learning methods to provide a visual intuition of important and potentially predictive structure in the data. We presented a reasoned approach to removing non-informative features and further reducing the dimension of the problem by correspondence analysis. After this, we were able to engineer a single, highly informative cluster membership feature, with very good potential as a diagnostic (classification) tool for similarly distributed data.
Appendix #
Here you can find the source code.
|
|